

Prediction of death rates for cardiovascular diseases and cancers
Abstract
Background
To estimate cardiovascular and cancer death rates by regions and time periods.
Design
Novel statistical methods were used to analyze clinical surveillance data.
Methods
A multicenter, population-based medical survey was performed. Annual recorded deaths from cardiovascular diseases were analyzed for all 195 countries of the world. It is challenging to model such data; few mathematical models can be applied because cardiovascular disease and cancer data are generally not normally distributed.
Results
A novel approach to assessing the biosystem reliability is introduced and has been found to be particularly suitable for analyzing multiregion environmental and healthcare systems. While traditional methods for analyzing temporal observations of multiregion processes do not deal with dimensionality efficiently, our methodology has been shown to be able to cope with this challenge.
Conclusions
Our novel methodology can be applied to public health and clinical survey data.
Abbreviations
-
- CVD
-
- cardiovascular disease
-
- MDOF
-
- multidegree of freedom
1 BACKGROUND
Cardiovascular disease (CVD) refers to a range of diseases affecting the heart and blood vessels including hypertension (high blood pressure), coronary heart disease and heart attacks, cerebrovascular diseases (e.g., stroke and heart failure), and various other heart diseases. Cancers are defined by the National Cancer Institute as diseases in which abnormal cells can divide and infiltrate nearby tissues. Cancers can arise in many parts of the body; thus, there is a wide range of cancer types, as shown below, some of which spread to other parts of the body through the blood and lymph systems. CVD and cancer are the leading causes of death worldwide, therefore analyzing bivariate statistics is important. This study is concerned with public health systems rather than health at the level of the individual. The research is not clinical in nature; the goal is to estimate the burden imposed by CVD and cancer on public health systems in different countries at any given time. We analyze mortality literature data for both CVDs [1-8] and cancer [9-29].
Assessing the reliability of healthcare systems and estimating excess mortality from CVDs using conventional statistical methods are challenging [30-35]. To achieve the latter goal over large areas, degrees of freedom are typically calculated for random variables governing dynamic biological systems. In principle, the reliability of a complex biological system can be accurately estimated if there are sufficient measurements or by using Monte Carlo simulations. For CVDs and cancers, however, data are scarce before 1990 [30]. Against this background, we introduce a novel method for assessing the reliability of biological and healthcare systems, to aid prediction and management of excess mortality from CVD. This study focused on cross-correlations in CVD and cancer deaths among countries within the same climatic zone. Worldwide health data and related research are readily available online [30].
Lifetime data analysis with the application of extreme value theory is widespread in the fields of medicine and engineering, [30]. A recent paper presented the arguments for and against using the upper distribution of life expectancy data [1]. A bivariate lifetime distribution is often assumed when analyzing statistical data [3]. A new approach that uses Clayton, Gumbel, and inverse Gaussian power variance functions, as well as conditional sampling and numerical approximation, was applied for survival analysis [2]. However, few studies have aimed to predict excess CVD and cancer mortality; this paper aimed to address this deficit.
In this paper, excess mortality from CVD is viewed as an unexpected event that may occur in any country at any time. The nondimensional factor 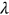 is used to predict CVD risk. Biological systems are influenced by environmental parameters that can be modeled as ergodic processes. The CVD and cancer incidence data for 195 countries during the period 1990–2019 were retrieved [30]. The biological system under consideration herein can be regarded as a multidegree of freedom (MDOF) dynamic system with highly interrelated regional components/dimensions. This study focused on predicting excess mortality rather than symptoms.
is used to predict CVD risk. Biological systems are influenced by environmental parameters that can be modeled as ergodic processes. The CVD and cancer incidence data for 195 countries during the period 1990–2019 were retrieved [30]. The biological system under consideration herein can be regarded as a multidegree of freedom (MDOF) dynamic system with highly interrelated regional components/dimensions. This study focused on predicting excess mortality rather than symptoms.
2 METHODS
Consider an MDOF biosystem subjected to random ergodic environmental influences. The other alternative is to view the process as being dependent on specific environmental parameters whose variation in time may be modeled as an ergodic process on its own. The MDOF biomedical response vector process 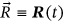 is measured and/or simulated over a sufficiently long time interval
is measured and/or simulated over a sufficiently long time interval 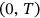 . Unidimensional global maxima over the entire time span
. Unidimensional global maxima over the entire time span 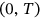 are denoted as
are denoted as 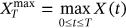 ,
, 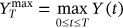 ,
, 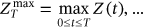 . By sufficiently long time
. By sufficiently long time 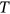 , one primarily means a large value of
, one primarily means a large value of 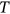 with respect to the dynamic system autocorrelation time.
with respect to the dynamic system autocorrelation time.
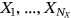 be consequent in the time local maxima of the bioprocess
be consequent in the time local maxima of the bioprocess 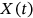 at monotonously increasing discrete time instants
at monotonously increasing discrete time instants 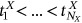 in
in 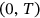 . The analogous definition follows for other MDOF biological system response components
. The analogous definition follows for other MDOF biological system response components 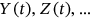 with
with 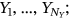
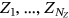 , and so on. For simplicity, all
, and so on. For simplicity, all 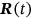 components, and therefore, its maxima are assumed to be nonnegative. The aim is to estimate system failure probability
components, and therefore, its maxima are assumed to be nonnegative. The aim is to estimate system failure probability
 ()
() ()
()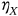 ,
, 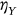 ,
, 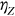 , … critical values;
, … critical values; 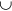 denotes logical unity operation «or»; and
denotes logical unity operation «or»; and 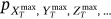 being joint probability density of the global maxima over the entire time span
being joint probability density of the global maxima over the entire time span 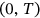 .
.In practice, however, it is not feasible to estimate the latter joint probability distribution directly 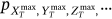 due to its high dimensionality and available data set limitations. In other words, the time instant when either
due to its high dimensionality and available data set limitations. In other words, the time instant when either 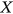 exceeds,
exceeds, 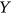 exceeds,
exceeds, 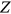 exceeds, and so on, the system is regarded as immediately failed. Fixed failure levels
exceeds, and so on, the system is regarded as immediately failed. Fixed failure levels 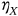 ,
, 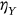 ,
,  , … are, of course, individual for each unidimensional response component of
, … are, of course, individual for each unidimensional response component of 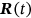 .
. 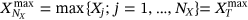 ,
, 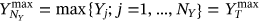 ,
, 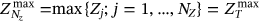 , and so on, see Naess and Gaidai [32] and Naess and Moan [49].
, and so on, see Naess and Gaidai [32] and Naess and Moan [49].
Next, the local maxima temporal instants 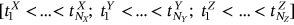 in monotonously nondecreasing order being sorted into one single merged synthetic time vector
in monotonously nondecreasing order being sorted into one single merged synthetic time vector 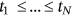 . Note that
. Note that  ,
, 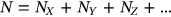 . In this case,
. In this case, 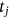 represents the local maxima of one of the MDOF biosystem response components either
represents the local maxima of one of the MDOF biosystem response components either 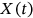 ,
, 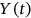 , or
, or 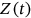 , and so on. That means that having
, and so on. That means that having 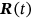 time record, one just needs to continuously and simultaneously screen for unidimensional response component local maxima and record its exceedance of the MDOF limit vector
time record, one just needs to continuously and simultaneously screen for unidimensional response component local maxima and record its exceedance of the MDOF limit vector 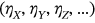 in any of its components
in any of its components 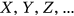 . The local unidimensional response component maxima are merged into one temporal nondecreasing vector
. The local unidimensional response component maxima are merged into one temporal nondecreasing vector 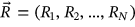 in accordance with the merged time vector
in accordance with the merged time vector 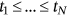 . That is to say, each local maxima
. That is to say, each local maxima 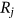 is the actual encountered local maxima corresponding to either
is the actual encountered local maxima corresponding to either 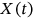 ,
, 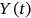 , or
, or 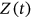 , and so on. Finally, the unified limit vector
, and so on. Finally, the unified limit vector 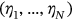 is introduced with each component
is introduced with each component 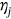 is either
is either 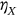 ,
, 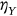 , or
, or 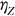 and so on, depending on which of
and so on, depending on which of  or
or 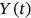 or
or 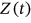 , and so forth, corresponds to the current local maxima with the running index
, and so forth, corresponds to the current local maxima with the running index 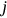 .
.
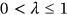 is introduced to artificially simultaneously decreases limit values for all biosystem response components, namely, the new MDOF limit vector
is introduced to artificially simultaneously decreases limit values for all biosystem response components, namely, the new MDOF limit vector 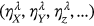 with
with 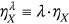 ,
,  ,
, 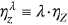 , … is introduced. The unified limit vector
, … is introduced. The unified limit vector 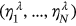 introduced with each component
introduced with each component 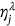 is either
is either 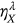 ,
, 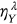 , or
, or 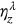 and so on. The latter automatically defines probability
and so on. The latter automatically defines probability 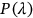 as a function of
as a function of 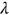 ; note that
; note that 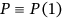 from Equation (1). Nonexceedance probability
from Equation (1). Nonexceedance probability  can be now estimated as follows:
can be now estimated as follows:
 ()
()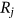 values is not always negligible; thus, the following one-step (i.e., “conditioning level”;
values is not always negligible; thus, the following one-step (i.e., “conditioning level”; 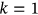 ) memory approximation is introduced
) memory approximation is introduced
 ()
()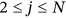 (called here conditioning level
(called here conditioning level  ). Approximation being introduced by Equation (4) may be further expressed as
). Approximation being introduced by Equation (4) may be further expressed as
 ()
()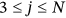 (will be called conditioning level
(will be called conditioning level 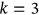 ) and so on. The motivation is to monitor each independent failure that happened locally first in time, thus avoiding cascading local intercorrelated exceedances [36-48].
) and so on. The motivation is to monitor each independent failure that happened locally first in time, thus avoiding cascading local intercorrelated exceedances [36-48].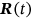 was assumed ergodic and therefore stationary, probability
was assumed ergodic and therefore stationary, probability 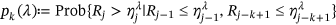 for
for 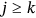 will be independent of
will be independent of 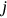 but only dependent on conditioning level
but only dependent on conditioning level 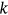 . Thus, the nonexceedance probability can be approximated as in the Naess–Gaidai method, see [32, 49], where:
. Thus, the nonexceedance probability can be approximated as in the Naess–Gaidai method, see [32, 49], where:
 ()
()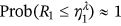 , as the design failure probability is usually very small. Further, it is assumed that
, as the design failure probability is usually very small. Further, it is assumed that 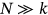 . Note that Equation (5) is similar to the well-known mean up-crossing rate equation for the probability of exceedance [32, 49]. There is observed convergence with respect to conditioning parameter
. Note that Equation (5) is similar to the well-known mean up-crossing rate equation for the probability of exceedance [32, 49]. There is observed convergence with respect to conditioning parameter 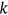
 ()
()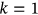 turns into the quite well-known nonexceedance probability relationship with the mean up-crossing rate function
turns into the quite well-known nonexceedance probability relationship with the mean up-crossing rate function
 ()
()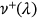 is the mean up-crossing rate of the response level
is the mean up-crossing rate of the response level 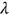 for the above assembled nondimensional vector
for the above assembled nondimensional vector 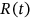 assembled from scaled MDOF biosystem response
assembled from scaled MDOF biosystem response 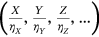 . The proposed methodology can also treat nonstationary cases. An illustration of how the methodology can be used to treat nonstationary cases is provided as follows. Consider a scattered diagram of
. The proposed methodology can also treat nonstationary cases. An illustration of how the methodology can be used to treat nonstationary cases is provided as follows. Consider a scattered diagram of 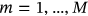 bioenvironmental states, with each short-term bioenvironmental state having probability
bioenvironmental states, with each short-term bioenvironmental state having probability 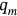 so that
so that 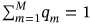 . The corresponding long-term equation is then
. The corresponding long-term equation is then
 ()
()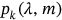 being the same function as in Equation (7) but corresponding to a specific short-term environmental state with the number
being the same function as in Equation (7) but corresponding to a specific short-term environmental state with the number 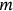 . Note that this statistical model has already been validated [47, 50-52].
. Note that this statistical model has already been validated [47, 50-52].3 RESULTS
Prediction of CVD and cancer has long been a target in the fields of epidemiology and mathematical biology. Public health systems are dynamic, highly nonlinear, multidimensional, and spatially diverse systems that are challenging to analyze. Previous studies have used a variety of approaches to predict CVD and cancer cases. In this section, the above-described methodology is applied to real-world CVD data sets for all countries of the world.
The statistical data in the present section are from the “Our World in Data” website [30], which provides annual CVD death rates for all countries for the period 1990–2019. The death rates for the 195 countries (components 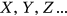 ) constitute 195 dimensional (195D) data for a dynamic biological system.
) constitute 195 dimensional (195D) data for a dynamic biological system.
General failure limits (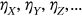 ), that is, CVD thresholds, are less intuitive than setting failure limits for each individual country according to its population, such that
), that is, CVD thresholds, are less intuitive than setting failure limits for each individual country according to its population, such that 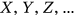 are equal to the annual death rate of a given country. The death rate for cancer is lower than that for CVD, but it is typically more painful to die from cancer. In this paper, the “failure limit” for cancer is lowered fourfold to match that for CVD.
are equal to the annual death rate of a given country. The death rate for cancer is lower than that for CVD, but it is typically more painful to die from cancer. In this paper, the “failure limit” for cancer is lowered fourfold to match that for CVD.
 ()
()Each maximum, such as  , is inserted into single time series according to its temporal occurrence (denoted by subscript
, is inserted into single time series according to its temporal occurrence (denoted by subscript 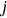 ).
).
Figure 1 presents the annual deaths from CVD and cancer by country and year. Figure 2 presents the number of new deaths as a 195D vector 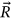 . Data for Uzbekistan were excluded from the analysis because they were regarded as outliers.
. Data for Uzbekistan were excluded from the analysis because they were regarded as outliers. 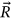 was assembled from different regional components, that is, CVD data sets. Index
was assembled from different regional components, that is, CVD data sets. Index 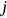 is a running index of local maxima encountered in the “non-decreasing” time series.
is a running index of local maxima encountered in the “non-decreasing” time series.


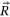 , as a percentage of the population of the corresponding country. The cancer rate was increased fourfold to match that of CVD.
, as a percentage of the population of the corresponding country. The cancer rate was increased fourfold to match that of CVD.Overall, there is a clear East–West divide in the CVD death rates. Rates across North America and Western/Northern Europe tended to be lower than those across Eastern Europe, Asia, and Africa. For most of Latin America, the rates were moderate. As an example, in France, the age-standardized CVD death rate was around 86 per 100,000 in 2017, while across Eastern Europe, it was around five times higher (400–500 per 100,000). Uzbekistan had the highest rate of 724 per 100,000.
Figure 3 presents the predicted annual CVD death rates (percentage relative to the entire population of a given country) over 100 years, extrapolated from Equation (10). 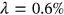 was used as a cut-off value. The 95% confidence intervals (CIs) were calculated. According to Equation (5),
was used as a cut-off value. The 95% confidence intervals (CIs) were calculated. According to Equation (5), 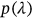 is directly related to the target failure probability (
is directly related to the target failure probability (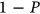 ) derived from Equation (1). Therefore, system failure probability can be estimated as
) derived from Equation (1). Therefore, system failure probability can be estimated as 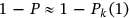 . Note that, in Equation (6),
. Note that, in Equation (6), 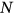 corresponds to the total number of local maxima in response vector
corresponds to the total number of local maxima in response vector 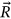 . Conditioning parameter
. Conditioning parameter  was found to be sufficient because of the convergence of
was found to be sufficient because of the convergence of 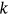 (see Equation 6). In Figure 3, the 95% CIs are relatively narrow, which represents an advantage of the proposed method. Table 1 compares 100-year predictions based on data for 15- and 30-year periods. The 15-year data set was derived from the full 30-year data set by omitting odd years. The 95% CIs were wider for the truncated data set, as expected.
(see Equation 6). In Figure 3, the 95% CIs are relatively narrow, which represents an advantage of the proposed method. Table 1 compares 100-year predictions based on data for 15- and 30-year periods. The 15-year data set was derived from the full 30-year data set by omitting odd years. The 95% CIs were wider for the truncated data set, as expected.

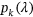 . The critical level is indicated by a star. The 95% confidence intervals are indicated by dotted lines. The percentage of the population is represented by the horizontal axis. Left: Predictions based on 30 years of data; Right: predictions based on 15 years of data.
. The critical level is indicated by a star. The 95% confidence intervals are indicated by dotted lines. The percentage of the population is represented by the horizontal axis. Left: Predictions based on 30 years of data; Right: predictions based on 15 years of data.| Predicted death rate (%) | 95% CI, lower bound | 95% CI, upper bound | |
|---|---|---|---|
| 30-year data set | 0.942 | 0.909 | 0.966 |
| 15-year data set | 0.914 | 0.879 | 0.949 |
- Abbreviation: CI, confidence interval.
The predicted average annual CVDs over the next 100 years, among all years and countries, were found below 1%. Our methodology uses available data efficiently by assuming that healthcare system data sets are multidimensional and extrapolates death rates even when the data set is relatively limited. The predicted nondimensional factor 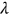 , indicated by the star in Figure 3, represents the probability of excess CVD mortality for any given country. Our method could be applied to predict cancer clusters, rather than merely death rates over time, which would be of high practical importance.
, indicated by the star in Figure 3, represents the probability of excess CVD mortality for any given country. Our method could be applied to predict cancer clusters, rather than merely death rates over time, which would be of high practical importance.
4 CONCLUSIONS
Traditional methods for assessing the reliability of healthcare systems on the basis of time series data do not efficiently deal with systems characterized by high dimensionality and cross-correlations. The main advantage of our methodology is its ability to assess the reliability of high-dimensional nonlinear dynamic systems. Despite its simplicity, the novel multidimensional modeling strategy introduced herein can be used for accurate forecasting of CVD death rates in individual countries.
We analyzed 195D data, that is, CVD and cancer death rates for 195 countries worldwide, for the period 1990–2019. A novel method for analyzing the reliability of a multidimensional biosystem was applied and the mechanisms of the proposed method were described in detail. Direct measurements and Monte Carlo simulations are both suitable for assessing the reliability of dynamic biological systems; however, the complexity and high dimensionality of such systems necessitate the further development of robust and accurate techniques that can use limited data sets in an efficient manner.
This study predicted an average annual death rate for CVD over a 100-year period of about 1% across countries and years. Under current national health management approaches, CVDs will continue to represent a threat to the health of the world population.
This study introduced a general-purpose, robust, and easy-to-apply method for analyzing the reliability of multidimensional systems. The method has previously been validated by application to a wide range of simulation models but only in the context of one-dimensional systems; in general, highly accurate predictions were obtained. Both measurement and numerically simulated time series data can be analyzed. Applying the method to the data set used in this study yielded reasonable confidence intervals, indicating that it could serve as a useful tool for reliability studies of various nonlinear dynamic biological systems. Finally, the suggested methodology has many potential public health applications beyond the prediction of CVD death rates.
AUTHOR CONTRIBUTIONS
Oleg Gaidai: Conceptualization (equal). Yihan Xing: Validation (equal). Rajiv Balakrishna: Investigation (equal). Jiayao Sun: Methodology (equal). Xiaolong Bai: Validation (equal).
ACKNOWLEDGMENTS
None.
CONFLICT OF INTEREST STATEMENT
The authors declare no conflict of interest.
ETHICS STATEMENT
Not applicable.
INFORMED CONSENT
Not applicable.
Open Research
DATA AVAILABILITY STATEMENT
Data sets analyzed during the current study are available online at https://ourworldindata.org/causes-of-death (“Our World in Data” [30]).

