Automatic lumen and anatomical layers segmentation in IVOCT images using meta learning
Abstract
Automated analysis of the vessel structure in intravascular optical coherence tomography (IVOCT) images is critical to assess the health status of vessels and monitor coronary artery disease progression. However, deep learning-based methods usually require well-annotated large datasets, which are difficult to obtain in the field of medical image analysis. Hence, an automatic layers segmentation method based on meta-learning was proposed, which can simultaneously extract the surfaces of the lumen, intima, media, and adventitia using a handful of annotated samples. Specifically, we leverage a bi-level gradient strategy to train a meta-learner for capturing the shared meta-knowledge among different anatomical layers and quickly adapting to unknown anatomical layers. Then, a Claw-type network and a contrast consistency loss were designed to better learn the meta-knowledge according to the characteristic of annotation of the lumen and anatomical layers. Experimental results on the two cardiovascular IVOCT datasets show that the proposed method achieved state-of-art performance.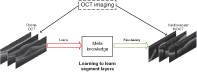
CONFLICT OF INTEREST STATEMENT
The authors have stated explicitly that there are no conflicts of interest in connection with this article.
Open Research
DATA AVAILABILITY STATEMENT
Data underlying the results presented in this paper was not publicly available at this time but may be obtained from the sponsor upon reasonable request.