

Recent advances of Transformers in medical image analysis: A comprehensive review
Abstract
Recent works have shown that Transformer's excellent performances on natural language processing tasks can be maintained on natural image analysis tasks. However, the complicated clinical settings in medical image analysis and varied disease properties bring new challenges for the use of Transformer. The computer vision and medical engineering communities have devoted significant effort to medical image analysis research based on Transformer with especial focus on scenario-specific architectural variations. In this paper, we comprehensively review this rapidly developing area by covering the latest advances of Transformer-based methods in medical image analysis of different settings. We first give introduction of basic mechanisms of Transformer including implementations of selfattention and typical architectures. The important research problems in various medical image data modalities, clinical visual tasks, organs and diseases are then reviewed systemically. We carefully collect 276 very recent works and 76 public medical image analysis datasets in an organized structure. Finally, discussions on open problems and future research directions are also provided. We expect this review to be an up-to-date roadmap and serve as a reference source in pursuit of boosting the development of medical image analysis field.
1 INTRODUCTION
For medical analysis, medical image is one of the most abundant modalities. With the increasing development of computer vision (CV), the medical image analysis can contribute to the clinical practice of doctors. Some specific CV tasks on medical images can be, to some extent, associated with the guide and aid for the doctors. For instance, the segmentation task in CV can help the doctor pick out the abnormal region, which reflects the symptom of disease and provide the preliminary information for the corresponding medical intervention. On the other hand, medical image analysis differs from the general CV task owing to the property of medical images. The medical image data set tends to be relatively small, which make some framework that have performed well in CV fail the medical image analysis task expectancy.
Despite the particularity of medical image analysis, there still exists a strong relation between the CV and medical image analysis. Hence, the shift of CV mainstream method has also been reflected in automatic analysis of medical images. Since the deep learning reshaped the development of CV, convolutional neural network (CNN) has been one of the most influencing frameworks in image processing. Correspondingly, previous attempts had been made to employ the CNN to the detection, segmentation, and other visual tasks on various medical image modalities, such as computed tomography (CT), ultrasound (US), magnetic resonance imaging (MRI). The convolution operation, on which CNNs were generally based, proved to be excellent in local feature extraction.
However, the shortcoming of convolution operation outbroke with the occurrence of Transformer structure tailored for images. Transformer network was initially launched for the natural language processing (NLP). The global dependency of attention mechanism made the Transformer dominate NLP in a short period. Afterward, the introducing of Transformer to the image processing, namely the vision Transformer, was shown to outperform the CNN largely in terms of image recognition. Other than image recognition, many visual tasks, such as image segmentation, image reconstruction also accepted the Transformer structure. Nevertheless, the Transformer structure brought a sharp improvement in efficiency yet a larger consumption of data scale and computation source. Notably, medical image analysis, with a scarcity of data scale, may suffer from the shortcoming of Transformer. It still remains an open question as for how to balance the efficiency of Transformer with its overwhelming computation cost.
In this paper, many attempts to solve this dilemma have been introduced. Considering the complexity of clinical circumstance and disease symptom, many researchers have proposed many innovative methods to utilized the Transformer in medical imaging analysis. Some fuse the Vision Transformer with other network while others tailor the Vision Transformer network according to the specific requirement of clinical demand. To demonstrate these Transformer-based methods more comprehensively and systematically, these attempts are arranged according to their corresponding visual tasks in CV and target diseases. The organization of this paper as follows. Section 2 introduces the mechanism of Transformer and Vision Transformer. Sections 3–9 categorizes the different applications of Vision Transformer in medical imaging. Section 10 introduces some public medical imaging datasets. Section 11 concludes the latest Transformer-based works in medical imaging and discusses the further development.
2 MECHANISMS OF TRANSFORMER
Initially proposed in Vaswani et al.,1 Transformer has shown to perform an excellent task in NLP. In fact, the powerful weapon for Transformer: the global receptive fields and the long-range dependency also applies to the vision task with a trick of image patching. In Section 2, the selfattention module, positional encoding and the Transformer structure are introduced as the preparation for the Transformer-based works in Sections 3–9.
2.1 Self-attention
Self-attention is a mechanism adopted in Transformer (as is shown in Figure 1) to achieve the task of sequence labelling. In a seq-to-seq task, in which the inputs are vector sets instead of a single vector, the model may find it difficult to extract the contextual information. Thus, the self-attention is introduced with the help of Scaled dot-product. The contextual weight of each vector is obtained after the Scaled dot-product in pairs and a Softmax operation.

2.1.1 Scaled dot-product
 ()
() ()
()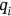 ,
, 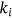 ,
, 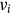 are shaped in the form of matrixes. With the matrix Q, K, the attention weight can be calculated by multiplying Q with K. After a
are shaped in the form of matrixes. With the matrix Q, K, the attention weight can be calculated by multiplying Q with K. After a 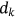 (dimension) division and a Softmax operation, the compressed attention weight is assigned to the V matrix. In conclusion, the Scaled dot-product attention can be described mathematically as follows:
(dimension) division and a Softmax operation, the compressed attention weight is assigned to the V matrix. In conclusion, the Scaled dot-product attention can be described mathematically as follows:
 ()
()2.1.2 Multi-Head Attention
 ()
()2.2 Positional encoding
Positional encoding is an effective method to retain positional information, which has also been previously adopted in CNN or RNN. As Transformer take the data as a whole with no regard to distance within sequences, the position information of the data is missing. Therefore, position encoding in Transformer is not complementary to recurrent or convolution, as it tends to do in CNN or RNN, but an essential indicator that carries all of the positional information in Transformer, whether this positional information is relative or absolute.
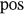 stands for the position index of a particular word. For the odd dimension and even dimension of the positional encoding, different sinusoid functions are adopted as follows:
stands for the position index of a particular word. For the odd dimension and even dimension of the positional encoding, different sinusoid functions are adopted as follows:
 ()
()Owing to the property of sinusoid function: product to sum, 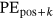 can be represented as a linear function of
can be represented as a linear function of 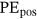 .
.
2.3 Transformer architecture
Designed for sequence-to-sequence tasks, Transformer adopts the encoder-to-decoder architecture, like other excellent neural sequence transduction models. A typical Transformer consists of blocks for Multi-Head Attention, masked Multi-Head Attentionattention,Feed Forward, and layer normalization.
2.3.1 Encoder
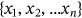 , after the Multi-Head Attention block, the sequence gets normalized and added by the input before the Multi-Head Attention. Then, the data sequence gets processed through a Feed Forward layer and a residual connection, an output sequence Z =
, after the Multi-Head Attention block, the sequence gets normalized and added by the input before the Multi-Head Attention. Then, the data sequence gets processed through a Feed Forward layer and a residual connection, an output sequence Z = 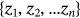 is fed to decoder. The computation process of Feed Forward layer can be depicted as follows:
is fed to decoder. The computation process of Feed Forward layer can be depicted as follows:
 ()
()2.3.2 Decoder
Decoder of the Transformer contains three layers. The target of decoder is to generate the output sequence of the whole Transformer model based on the output of the encoder. Notably, the bottom Multi-Head Attention employed in decoder gets masked. As the sequence-to-sequence task takes sequences as both input and output, the mask operation can cut off the influence from the subsequent positions. The following Multi-Head Attention layer and Feed Forward layer are similar to those in the encoder part.
In this review, we consider various types of Transformer models used in the field of medical image analysis in different settings.
3 MEDICAL IMAGE SEGMENTATION
Medical images are suitable for revealing the symptoms of the disease, which can be valuable for both diagnosis and treatment. However, from the pixel-wise perspective, only some part of a medical image make contribution to the latter diagnosis and treatment, namely the tumor part of a CT image. Hence, it remains an important and challenging task for researchers to segment the targeted region, whether the infected area or an abnormal organ, of a medical image. Thankfully, many medical image researchers have introduced the prevalent framework in computer vison: Transformer to solve this automatic medical image segmentation. Some of their efforts are summarized in Table 1.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| RANT2 | Laryng | Throat | None |
| MBT-Net3 | Fundus | Eye | Corneal |
| PCAT-UNet4 | Fundus | Retinal | Vessel |
| TransBridge5 | Echocar | Cardiac | Left ventricle |
| GT-Unet6 | X-ray | Tooth | Rootcanal |
| AGMB-Transformer7 | X-ray | Tooth | Rootcanal |
| Chest l-Transformer8 | X-ray | Chest | None |
| GuifangZ9 | X-ray | Catheter | Guide-wire |
| MSAM10 | PETCT | Lung | Lung cancer |
| TransDeepLab11 | Multimodality | Pure Transformer | 2D |
| TransNorm12 | Multimodality | UNet-based | 2D |
| EG-TransUNet13 | Multimodality | UNet-based | 2D |
| HRSTNet14 | Multimodality | Others | None |
| ScaleFormer15 | Multimodality | CNN-based | None |
| TFCNs16 | Multimodality | Others | None |
| Karimi17 | Multimodality | Pure Transformer | 3D |
| TransUNet18 | Multimodality | UNet-based | 2D |
| UTNet19 | Multimodality | UNet-based | 2D |
| MedT20 | Multimodality | CNN-based | None |
| SwinUnet21 | Multimodality | UNet-based | 2D |
| AFTer-UNet22 | Multimodality | UNet-based | 3D |
| MissFormer23 | Multimodality | Pure Transformer | 2D |
| DS-TransUNet24 | Multimodality | UNet-based | 2D |
| PMTrans25 | Multimodality | CNN-based | None |
| UTran26 | Multimodality | UNet-based | 2D |
| LeViT-UNet27 | Multimodality | Others | None |
| CASTformer28 | Multimodality | GAN | None |
| HiFormer29 | Multimodality | CNN-based | None |
| LViT30 | Multimodality | Others | None |
| DFormer31 | Multimodality | UNet-based | 3D |
| MCTrans32 | Multimodality | CNN-based | None |
| HyLT33 | Multimodality | CNN-based | None |
| TranFuse34 | Multimodality | CNN-based | None |
| UTrans26 | Multimodality | UNet-based | 2D |
| Segtran35 | Multimodality | CNN-based | None |
| Li36 | Multimodality | UNet-based | 2D |
| TransClaw UNet37 | Multimodality | UNet-based | 2D |
| TransAttUNet38 | Multimodality | UNet-based | 2D |
| nnFormer39 | Multimodality | Pure Transformer | 3D |
| VT-UNet40 | Multimodality | Pure Transformer | 3D |
| MSHT41 | Multimodality | CNN-based | None |
| USegTransformer42 | Multimodality | CNN-based | None |
| TUnet43 | Multimodality | UNet-based | 2D |
| ViTBIS44 | Multimodality | Pure Transformer | 2D |
| Atlas-ISTN45 | Multimodality | Pure Transformer | 3D |
| Shen Jiang46 | Micro | Celluar | Tissue |
| CellDETR47 | Micro | Cell | Cell |
| DFANet48 | MRI | Bone | Osteosarcoma |
| Liqun Huang49 | MRI | Brain | Glioma |
| TransBTS50 | MRI | Brain | Brain tumor |
| Swin-UNETR51 | MRI | Brain | Brain tumor |
| BiTr-Unet52 | MRI | Brain | Brain tumor |
| 3D Transformer53 | MRI | Brain | Brain region |
| MRA-TUNet54 | MRI | Cardiac | Atrial |
| HybridCTrm55 | MRI | Brain | Brain tumor |
| Zheyao G56 | MRI | Cardiac | Right ventricle |
| TransConver57 | MRI | Brain | Brain tumor |
| METran58 | MRI | Brain | Stroke |
| SwinBTS59 | MRI | Brain | Braintumor |
| BTSwin-Unet60 | MRI | Brain | Braintumor |
| UTransNet61 | MRI | Brain | Stroke |
| TF-Unet62 | MRI | Cardiac | Atrial |
| CST63 | MRI | Colorectal | Colorectalcancer |
| SpecTr64 | HSI | None | None |
| BAT65 | Dermo | Skin | Melanoma |
| FAT-Net66 | Dermo | Skin | Melanoma |
| Swin-PANet67 | Dermo | Skin | Melanoma |
| Polyp-PVT68 | Colonos | Colorectal | Poly |
| SwinE-Net69 | Colonos | Colorectal | Poly |
| Cotr70 | CT | Multiorgan | 3D organ |
| PHTrans71 | CT | Multiorgan | Abonominal |
| COTRNet72 | CT | Kidney | Kidney cancer |
| HT-Net73 | CT | Multiorgan | Cross region |
| UCATR74 | CT | Brain | Stroke |
| CCAT-net75 | CT | Chest | COVID-19 |
| Danfeng76 | CT | Lung | Lung cancer |
| CAC-EMVT77 | CT | Cardica | CAC |
| DTNet78 | CT | Bone | Cranio |
| Liu79 | ABVS | Breast | Breast tumor |
| MS-TransUNet80 | Multi | UNet | 2D |
3.1 X-ray or radiographic images
3.1.1 Tooth root segmentation
In root canal therapy for periodontitis, both underfilling and overfilling may have a negative influence on patients. However, the automatic assessment for root canal therapy has to be based on an accurate tooth root segmentation. Owing to the fuzzy boundary of tooth root, Li et al.6 proposed an AGMB-Transformer to achieve an efficient and accurate segmentation of tooth root. For the ambiguous boundary and low-resolution imaging, AGMB-Transformer designed the anatomy feature extractor and multibranch Transformer network. Experimental results showed the AGMB-Transformer's superior performance compared with ResNet, GCNet, and BoTNeT. The pipeline for AGMB-Transformer is shown in Figure 2.

3.1.2 Lung disease segmentation
Despite the popularity of weakly supervised deep learning models, these models may not apply to chest radiograph effectively. On the one hand, the lung image is mainly but rigorously symmetrical, which may confuse the learning models; On the other hand, some regions of the chest may be immune to certain diseases while these hidden connections tend to be ignored by the weakly supervised deep learning model. Thus, Gu et al.8 proposed a novel Chest L-Transformer to segment the thoracic disease region and diagnose the disease. Specifically, Chest-L-Transformer employed CNN to achieve the local feature extraction and the Transformer to distribute different attention on the chest radiograph regions with positional embedding. Experimental results on SIIM-ACR Pneumothorax Segmentation datasets showed that Chest L-Transformer's performance.
3.2 MRI
3.2.1 Bone tumor segmentation
As one of the malignant bone tumors, osteosarcoma is highly resistant to chemotherapy and bears a high recurrence rate. For the diagnosis of osteosarcoma, MRI can greatly reflect the soft-tissue, which makes it acute to osteosarcoma. However, the MRI images are accompanied with huge amount data and serious noises. Thus, Wang et al.48 used an Edge Enhancement based Transformer (Eformer) for denoising of the input MRI image and a deep feature aggregation for real-time semantic segmentation (DFANET) to segment the osteosarcoma from the original MRI image of bone.
3.2.2 Brain tumor segmentation
Accounting for 80% of malignant brain tumors, glioma is difficult to automatically diagnosed due to its changeable appearance and ambiguous boundary. Transformer-based methods for glioma included.49-52, 55, 57, 59 Jiang et al.59 proposed a SwinBTS to introduce the SwinTransformer to a U-shape structure to fulfill the task of 3D brain tumor segmentation. With a fusion of convolution operation and attention mechanism, SwinBTS adopted the SwinTransformer as the encoder and decoder. Besides, Jiang et al. also designed an Enhanced Transformer Block based on selfattention to give a further feature extraction if the former encoder failed to grasp the crucial information from the image. SwinBTS proved to reach state-of-the-art results on BraTS 2019, BraTS 2020, and BraTS 2021.
3.2.3 Stroke segmentation
Shortage of blood supply may lead to damage of brain tissue and possibly causes an Ischemic stroke. For the assessment of brain tissue, a precise segmentation method is needed to note the boundary of lesion area. Wang et al.58 proposed a METrans, which intended to extract multiscale features to promote the segmentation quality of stroke lesion area. To be specific, Wang et al. introduced attention-based block: convolutional block attention module (CBAM) to the encoder-to-decoder structure. Meanwhile, to guarantee the presence of low-level features, Wang et al. supplemented the attention-based modules with three encoders for local details. Experimental results on ISLES2018 and ATLAS proved that METran outperformed the state-of-the-art methods in Dice.
3.2.4 Ventricle segmentation
For the diagnosis of many cardiovascular diseases, whether the cardiac structure can be made with high accuracy influences the assessment result. However, the precise segmentation of a right ventricle (RV) structure demands both short-axis (SA) images and long-axis (LA) images, posing a challenge for the current segmentation methods. Fusing the U-Net with Transformer, Chen et al.54 proposed an MRA-TUNet to achieve the segmentation of atrial and ventricle. The performance of MRA-TUNet was confirmed by the experimental results on ACDC and 2018 atrial segmentation challenge. For the ventricle segmentation, dive score of MRA-TUNet for left ventricle was 0.961 and 0.911 for the right; For the atrium, the dice score reached 0.923.
3.3 CT scans
3.3.1 Kidney cancer segmentation
Kidney cancer, as one of the most prevalent cancers all over the world, can be cured efficiently if detected at an early age. For automatic CT diagnosis of kidney cancer, variation of the kidney tumors' location, shape and other properties may pose a challenge for kidney tumor segmentation. Shen et al.72 proposed an end-to-end COTRNet fusing CNN with Transformer. Skip connection operations are also taken in the encoder-to-decoder structure. In 2021 kidney and kidney tumor segmentation challenge (kits21), COTRNet won the 22th place with a performance of 61.6% for average dice and 49.1% for surface dice and 50.52% for tumor dice.
3.3.2 Brain stroke segmentation
Among three main kinds of strokes, it is urgent to diagnose the acute ischemic stroke (AIS) considering its probable deteriorative symptoms. However, the boundary between healthy tissue and AIS legions is not indistinguishable for naked eyes at an early age, which makes the early intervention of AIS quite demanding for doctors. Luo et al. proposed a novel UCATR network to segment the target area, namely the AIS region. Fusing the attention mechanism and convolution operation, Luo et al.74 took an encoder-to-decoder for UCATR. For the encoder, UCATR chose to combine the CNN and Transformer for extracting both global and local features; for the decoder, UCATR utilized Transformer-based network to achieve a depiction of lesion area with high accuracy. Experimental results demonstrated that UCATR reached 73.58% for Dice similarity coefficients, which outperformed three other methods.
3.3.3 Craniomaxillofacial deformity segmentation
For patients who suffer from craniomaxillofacial deformities, their surgery may benefit from an accurate segmentation of bone and an intricate localization of anatomical landmark. Therefore, Lian et al.78 proposed an end-to-end DTNet to fulfill both the segmentation and the localization task. With two communicative branches, DTNet can not only retain sufficient local details, but also have a global receptive field. Besides, a regionalized dynamic learner (RDL) was designed to associate the neighboring landmarks. In comparison with other multitask networks, DTNet achieved the state-of-the-art.
3.3.4 Guide-wire segmentation
A successful cardiovascular interventional therapy requires a precise insertion of guide-wire to build a stent or deliver the drug. However, previous guide-wire segmentation networks are CNN-based and in lack of global dependency. Thus, Zhang et al.9 proposed a novel network introducing Transformer for guide-wire segmentation. Instead of merely taking a single frame as the input, Zhang et al. added some previous frames into input sequences. CNN was used to extract the features of the input frames while the Transformer was utilized for developing a long-range dependency. Considering the scarcity of catheter data set, this network is tested on datasets from three hospitals and experimental results showed that this model outperformed other segmentation models.
3.3.5 2D organ segmentation
The data set in medical imaging task is generally smaller in magnitude than in other computer vision tasks. Thus, Liu et al.71 proposed a PHTrans, which combines both the Transformer and CNN. PHTrans took advantage of the U-shaped encoder-to-decoder design and arranged a series of Trans&Conv blocks into the Parallel Hybrid Module. Inside the Trans&Conv block, a Transformer-based network and CNN-based network are paralleled so that the global and local features can be processed simultaneously. Experimental results showed the PHTrans's superior performance over other state-of-the-art models.
3.3.6 3D organ segmentation
Despite performing a perfect task in constructing a global dependency, pure Transformer is not competent at 3D medical image segmentation owing to its high computational and spatial complexities. Thus, Xie et al.70 combined a CNN and a deformable Transformer so as to balance the computation cost and accuracy. Evaluated on BCV data set, which included 11 major human organs, CoTr outperformed other CNN-based and Transformer-based methods.
3.4 Fundus or optical coherence tomography (OCT)
3.4.1 Corneal endothelial cell segmentation
Zhang et al.3 proposed an MBT-NET to address the blurred cell edge of corneal imaging, which was owing to the uneven reflection and tremor and movement of the corneal endothelial cell. Combing the architecture of CNN and Transformer, MBT-NET firstly used CNN to extract the local feature of the corneal endothelial cell image and give a global analysis through Transformer and residual connection. Experimental results on TM-EM3000 and Alisarine showed that MBT-NET outperformed the UNet and TransUNet on DICE, F1, SE, SP. Figure 3 demonstrates the MBT-NET's structure for segmentation.

3.4.2 Retinal vessel segmentation
The retinal vessel segmentation, if guaranteed high accuracy, can be beneficial to both ophthalmic and systemic disease diagnosis. However, this segmentation task is demanding in both local details and global information interaction, making pure CNN or pure Transformer unsuitable. Thus, Chen et al.4 proposed a PCAT-UNet, which took a U-shape structure with convolution operation to process local features and Transformer to construct global dependencies. In PCAT-UNet, Chen et al. designed two units: PCAT and FGAM for extraction and fusion of features. Experimental results on DRIVE and STARE data set demonstrated the PCAT-UNet's state-of-the-art performance.
3.5 Other modalities
3.5.1 Dermoscopy
Melanoma segmentation on dermoscopy image suffered from the varied appearance and vague boundaries of melanoma, which required sufficient local details. On the other hand, a larger receptive field was required for the accuracy of skin lesion segmentation. Pure CNN or pure Transformer can't tackle the problem of melanoma segmentation. Wu et al.66 propose a FAT-Net by introducing an extra Transformer branch to ensure the global context and sufficient local information. In FAT-Net, three notable adjustments are made on classical Transformer: (1) A dual encoder instead of singular encoder is adopted (2) Three feature adaptation modules (FAM) are employed (3) A memory-efficient decoder is used to combine the both the global context and the local information. These adjustments are proved by experimental results on ISIC 2016, ISIC 2017, ISIC 2018, and PH2.
3.5.2 Microscopy
Jiang et al.46 designed a gated position sensitive axial attention mechanism, which aimed to make Transformer-based network apply to small data set. Unlike the patch division that vision Transformer generally took, the proposed method chose to sample the input image iteratively. Besides, strip convolution module (SCM) and pyramid pooling module (PPM) were adopted to improve the network's capability in interpreting global context. Experimental results on three datasets showed this model outperformed other segmentation models in terms of F1 score and IoU. Instance segmentation of single-cell microscopy image requires much preliminary manual analysis. On the foundation of DETR, Tim et al.47 proposed a CellDETR to achieve an end-to-end instance segmentation of yeast cells. The main architecture of CellDETR was similar to DETR. Otherwise, CellDETR reduced the parameter number of DETR by 10 times and employed learned position encoding so that the network can fulfill the cell-specific instance segmentation with higher efficiency. The experimental result of CellDETR is compared with Mask R-CNN as well as U-Net and shows an improvement in both segmentation accuracy and inference runtime cost.
3.5.3 Endoscope
Laryngeal disease, whether lesion or tumor, can only be detected through an electronic laryngoscope owing to the larynx's distinct structure complexity. For the laryngeal lesion detection assisted by CV, few study focus on multiobject segmentation for electronic laryngoscope image. Hence, Pan et al.2 proposed a novel RANT, which utilized both the vision Transformer and CNN to for not only global context but also sufficient multiscale details. Specifically, four pyramid vision transformers (PVT) are employed to obtain the multiscale features while skip connections are made in each layer of PVT. Experimental results on two public laryngeal datasets showed that RANT achieved 76.63% and 88.77% for mIoU and 83.45% and 93.49% for mDSC.
3.5.4 Echocardiography
For left ventricle region segmentation, manual labelling may consume much time and leads to observer bias. Therefore, Deng et al.5 proposed a TransBridge that employed a lightweight Transformer-based model to segment the left ventricle region automatically with high efficiency. Combining the CNN and Transformer, TransBridge extracted the features using CNN encoder-to-decoder architecture and built a long-range dependency with Transformer. In comparison with CoTr,5 TransBridge reduced the total number of parameters by 78.7%, improved the dice coefficient to 91.4%.
3.5.5 Hyperspectral imaging
Unlike other medical imaging methods, Hyperspectral imaging is achieved by emitting a wide spectrum of light and analyzing the corresponding reflected and transmitted light, the band of which may be unrecognizable for naked eyes. Thus, Yun et al.64 proposed a SpecTr, which introduced Transformer and CNN for the segmentation of hyperspectral image. The authors treated the analysis of spectral band representation as a sequence-to-sequence prediction task. Taking a U-shape structure, the authors set Transformer as the encoder with a sparsity constraint tailored for the property of spectral band. Convolution operations were utilized in both encoder and decoder part for feature extraction and recovery.
3.6 Multimodality
3.6.1 Pure Transformer-based 2D segmentation
Huang et al.23 proposed a MISSFormer, based on pure Transformer to fulfill the task of medical image segmentation. A segmentation network based on pure Transformer was thought to be lacking in local details. To overcome the drawback of Transformer, Huang et al. made two modifications on Transformer-based structure: (1) MISSFormer replaced the typical feed-forward network (FFN) with an improved block: Enhanced Transformer block, which both boosted the global dependency and retained sufficient local details. (2) An enhanced transformer context bridge, designed in this paper, was employed for multiscale feature input for the network.
3.6.2 Pure Transformer-based 3D segmentation
Karimi et al.17 proposed a novel convolution-free 3D medical image segmentation method, which is based on pure Transformer. Specifically, Karimi et al. firstly divided the input 3D image into 3D patches and fed them into the attention-based encoder after a positional encoding. Eventually, the predicted patch represents the spatial distribution of the target region. Through experimental test on brain cortical plate, pancreas and hippocampus datasets, this model outperformed the CNN-based methods in terms of 3D medical image segmentation. Otherwise, for small training set, a pretraining may make the model's performance more superior.
3.6.3 CNN-based segmentation
There exist intrinsic inductive biases in CNN while Transformer requires a large data set. Therefore, combining these two structures can avoid the respective shortcomings. CNN-based Transformer attempts included.15, 20, 25, 26, 29, 32 From a scale-wise perspective, Huang et al. listed two major problems for those who replace the convolution layers with pure Transformer: intrascale and interscale. Targeting at these scale-wise problems, Huang et al.15 proposed a ScaleFormer. For intrascale problem, ScaleFormer designed a Dual-Axis MSA module to correlate the local features extracted from CNN; for interscale problem, ScaleFormer architected a novel Transformer-based network that can communicate between the regions in different scales. Experimental results on three datasets demonstrated the ScaleFormer surpassed the state-of-the-art result.
3.6.4 U-Net based 2D segmentation
U-Net design is naturally lacking in long-range dependency while the Transformer structure is deficit in low-level feature. Thus, a combination of U-Net and Transformer can achieve the balance between the global interaction and local sufficient details.12, 13, 18, 19, 21, 24, 26, 43 attempted to integrate both the U-shaped net with Transformer. Cao et al.21 proposed to integrate the Swin Transformer into a U-shape structure. This novel network, named as SwinUNet, was based on pure Transformer despite its look assimilated U-Net. To be specific, the Transformer-based network was based on Swin Transformer, which adopted the shifted window on the basis of a vanilla Transformer. Substituting the convolution modules in a typical U-Net encoder with Swin Transformer blocks for feature extraction, the SwinUNet's capability of grasping global context got largely improved. Meanwhile, the decoder in SwinUNet also employed the Swin Transformer to achieve the segmentation of the target region through a series of symmetric upsampling.
3.6.5 U-Net based 3D segmentation
Yan et al.31 proposed a D-Former to achieved the 3D medical image segmentation with high precision. This D-Former was capable of making full use of the depth information of the 3D medical images. It was notable that the design of D-Former31 improved the receptive field and boomed the information interaction while the computation of selfattention mechanism remained relatively low. Besides, D-Former achieved the positional encoding dynamically instead of using a singular function as in the vanilla Transformer.
3.6.6 GAN-based segmentation
You et al.28 proposed a CASTFormer, which intended to solve the prevalent drawbacks of Transformer-based models: simple tokenization scheme, scarcity of scale variety and inadequate texture. Based on GAN, CASTFormer consisted of both a generator and a discriminator. For the generator, You et al.28 employed a pyramid structure for sufficient multiscale features and proposed the class-aware Transformer modules to depict the target region from the input medical image. For the discriminator, You et al.28 integrated the ResNet-based encoder and Transformer-based encoder to give a discriminative result. Experimental results on three benchmarks showed that the CASTFormer reached an absolute improvement of 2.54%–5.88% in Dice Coefficients compared with the state-of-the-art result.
3.6.7 Other methods
Refs.14, 16, 27, 30 integrated Transformer with other existing efficient frameworks.
Specifically, Wei et al.14 proposed a HRSTNet which combined the HRNet and Swin Transformer. Li et al.16 adopted the structure of FC-DenseNet joined with ResLinear-Transformer (RL-Transformer) and convolutional linear attention block (CLAB) and proposed the TFCNs.16 Xu et al.27 proposed a LeViT-UNet, which combined both the LeViT and U-Net. Li et al.30 proposed a novel LViT, standing for “Language meets Vison Transformer” to introduce the annotation of medical text as a supplement of limited data set.
4 MEDICAL IMAGE CLASSIFICATION
Medical images, which tend to carry a variety of symptom-specific information, serve as important solid material for doctor to make diagnosis. Considering the fact that this diagnosis is largely dependent on the personal interpretation of medical images, the diagnosis result may be inevitably influenced by some subjective factors, such as individual experience and inducive bias. Thus, the accurate and stable medical image classification is required as a supplement for the diagnosis of doctors. Some state-of-the-art classification methods based on medical images have reached for both the degree of a specific disease and the detailed medical judgement. These medical image classification works based on Transformer are partially listed in the Table 2.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| ScoreNet81 | Histopath | Iissue | Breast cancer |
| T2T-ViT82 | Histopath | Cervical | Cervical cancer |
| IL-MCAM83 | Histopath | Colorectal | Colorectal cancer |
| IViT84 | Histopath | Kidney | pRCC |
| Guo85 | Histologic | Lung | Lung cancer |
| MIL-VIT86 | Fundus | Eye | Retinal disease |
| LAT87 | Fundus | Eye | Diabetic retinopathy |
| CheXT88 | X-ray | Chest | Abnormality |
| ViT89 | X-ray | Bone | Fracture |
| Park90 | X-ray | Chest | COVID-19 |
| FESTA91 | X-ray | Chest | COVID-19 |
| Liu92 | X-ray | Chest | COVID-19 |
| Covid-Trans93 | X-ray | Chest | COVID-19 |
| Tuan94 | X-ray | Chest | COVID-19 |
| MXT95 | X-ray | Chest | COVID-19 |
| Park96 | X-ray | Lung | COVID-19 |
| Van97 | X-ray | Multiorgan | None |
| Verenich98 | X-ray | Lung | Abnormality |
| KAT99 | WSI | Pathology | Endometrial |
| GTN100 | WSI | Lung | Lung cancer |
| TransPath101 | WSI | Pathology | Multiorgan |
| ScATNet102 | WSI | Pathology | Skin |
| TranMIL103 | WSI | Pathology | MIL |
| Gheflati104 | US | Breast | Breast cancer |
| POCFormer96 | US | Chest | COVID-19 |
| Qayyum105 | Photo | Toe | DFU |
| LLCT106 | OCT | Eye | Retina lesion |
| RadioTransformer107 | Multimodality | Pure Transformer | 2D |
| Matsokus108 | Multimodality | CNN-based | 2D |
| TransMed109 | Multimodality | CNN-based | None |
| SEViT110 | Multimodality | CNN-based | None |
| M3T111 | Multimodality | CNN-based | 3D |
| Islam112 | Micro | Blood | Malaria parasite |
| ViT-CNN113 | Micro | Lymph | Leukemia |
| BrainFormer114 | MRI | Brain | Brain disease |
| GlobalLocal115 | MRI | Brain | Brain age |
| STAGIN116 | MRI | Brain | Brain connectome |
| mfTrans117 | MRI | Hepatic | Hepatocellular carcinoma |
| MVT118 | Dermo | Skin | Melanoma |
| OOD115 | Dermo | Skin | None |
| DPE-BoTNeT119 | Dermo | Skin | Melanoma |
| CVM-Cervix120 | Cytopathology | Cervical | Cervical cancer |
| ViT& DenseNet121 | Colposcopy | Cervical | Cervical cancer |
| xViTCOS122 | CT + X-ray | Chest | COVID-19 |
| Hsu123 | CT | Chest | COVID-19 |
| Zhang124 | CT | Chest | COVID-19 |
| COViT-GAN125 | CT | Chest | COVID-19 |
| Wu126 | CT | Lung | Emphysema |
| costa127 | CT | Lung | COVID-19 |
| MIA-COV19D128 | CT | Chest | COVID-19 |
| CTNet129 | CT | Chest | COVID-19 |
| Scopeformer130 | CT | Brain | Intracranial hemorrhage |
| xia131 | CT | Pancrea | Pancreatic cancer |
| NoduleSAT132 | CT | Lung | Lung nodule |
| TransCNN133 | CT | Lung | COVID-19 |
| ParkS134 | CT | Lung | COVID-19 |
| covid-ViT135 | CT | Chest | COVID-19 |
| Uni4Eye136 | Ophthalmic | Eye | 2D + 3D |
4.1 X-ray or radiographic images
4.1.1 COVID-19 analysis
Considering the serious damage of COVID-19 on global health and economy, it is urgent to achieve a fast and effective diagnosis of COVID-19. Thus, authors in Refs,75, 90-96, 122-125, 127-129, 133, 135, 137 explored to achieve a rapid and accurate COVID-19 classification using Transformer-based architectures. Shome et al.93 proposed a Covid-Transformer to achieve the automatic examining of COVID-19 according to the X-ray image. To overcome the scarcity of data set, three open-source datasets got amalgamated into a 30 K high-quality data set. For binary classification of COVID-19, Covid-Transformer93 reached 98% for accuracy and 99% for AUC score; for multiclass classification (COVID-19, normal and pneumonia), Covid-Transformer93 achieved 92% for accuracy and 98% for AUC score. Tuan et al.94 proposed a novel network, which integrated both the convolution operation and selfattention mechanism for the classification of COVID-19. Tuan et al.94 designed this network to achieve the classification of three types: normal, pneumonia and COVID-19. To assess the severity of COVID-19, Tuan et al.94 constructed a data set, on which five deep learning models were tested. The result showed the efficiency of automatic chest X-ray diagnosis of COVID-19.
4.1.2 Fracture classification
Musculoskeletal diseases take the lead among the causes for disability. To intervene with musculoskeletal diseases as early as possible and work out the corresponding treatment for fracture, Tanzi et al.89 proposed a novel network to give the automatic classification on fracture subtype according to the CT scan of bones. Specifically, Tanzi et al.89 collected 4207 CT scan images with manual annotations and made the largest labeled data set of proximal femur fractures.89 Superior to the CNN-based methods, this Transformer-based network reached 0.77 for precision, 0.76 for recall and 0.77 for F1-score.
4.1.3 Multiorgan classification
For multiview medical image analysis, images from different views have to be combined. Although these images reflect the same object, the variations in perspective may arouse huge difference in appearance, thus posing challenges to registration. When the registration can not be finished, images from multiple angles can only be integrated through a global fusion of feature vectors. Therefore, Van et al.97 proposed a novel network that examined the spatial feature maps and associate the features extracted from unregistered views. Experimented on multiview mammography and chest X-ray datasets, this model outperformed the previous methods.
4.2 MRI
4.2.1 Brain disease classification
Brain diseases, which leaves no obvious structural lesion, can be reflected through the functional magnetic resonance imaging (fMRI). While functional connectivity has been widely taken as the basic feature in fMRI disease classification, the calculation of functional connectivity may rely too much on predefined regions of interests but jumps voxel-wise details. Thus, Dai et al.114 proposed a BrainFormer, which utilized Transformer for extracting global relations and 3D convolution to supplement the local details. Afterward, a single-stream model was set in BrainFormer114 to combine both the local and global information.
4.2.2 Brain age classification
With the help of deep learning, brain age can be estimated rapidly according to brain MRI result. However, previous automatic methods failed to obtain the global information but only concentrate on the local information. Thus, He et al.115 proposed a novel global-local Transformer, which fuse both global and local information for brain age estimation. Specifically, He et al.115 proposed two pathways respectively for global and local information, which got integrated through an attention mechanism. Evaluation on eight public datasets proved the global-local Transformer's performance. Figure 4 illustrated the global-local Transformer and multipatch age prediction in He et al.115

4.2.3 Brain connectome analysis
The temporal correlation in functional neuroimaging modalities can reflect the cross-region functional connectivity (FC) within the brain. Given the network-like property of these connectivity, graph neural networks (GNN) have been introduced to generate the graph representation of brain connectome. However, such attempts fail to incorporate the fluctuating property of functional connectivity network. Kim et al.116 proposed a STAGIN to model a dynamic graph representation of brain connectome. Apart from the GNN structure, Transformer encoder was also used in STAGIN116 to extract the global features. The performance of STAGIN has been validated on HCP-Rest and the HCP-Task datasets.
4.2.4 Hepatocellular carcinoma classification (HCC)
A preliminary preparation for the treatment of HCC is to examine the symptom of HCC quantitatively through the multiphase contrast-enhanced magnetic resonance imaging (CEMRI). Former CNN-based attempts for HCC measurement are lacking in long-range dependency establishment and multiphase CEMRI information selection. Therefore, Zhao et al.117 proposed a multifunction Transformer regression network (mfTrans-Net), which introduced attention mechanism for HCC qualitative measurement. To be specific, three CNN-based encoders were firstly parallelized to extract the features of CEMRI images. Nonlocal Transformer was set then to grasp the long-range dependencies. A multilevel training strategy was adopted for mfTrans-Net to improve the performance of HCC qualitative measurement.
4.3 CT
4.3.1 Emphysema classification
Emphysema can lead to the enlargement of alveoli, which may damage the lung. Based on the CT examine, emphysema is classified as three types: centrilobular emphysema (CLE), panlobular emphysema (PLE), and paraseptal emphysema (PSE). Considering the three types of emphysema demands different methods of treatment, Wu et al.126 proposed CT-based emphysema classification model which was inspired by the structure of vision Transformer. Wu et al.126 sliced the large patches obtained from the original CT images into sequences of patch embedding, which got fed into Transformer encoder after a positional encoding. Afterward, a softmax layer was utilized to give the final classification of emphysema subtype.
4.3.2 Lung nodule classification
The automatic diagnosis for multiple pulmonary nodules is crucial to clinical practice of pulmonary nodule treatment. However, previous studies tend to place emphasis on the single nodule, which may miss the correlation between nodules. Thus, Yang et al.132 proposed a novel NoduleSAT based on multiple instance learning (MIL) approach. NoduleSAT132 examined the patient's multiple nodules as a whole and analyzed the relations between multiple pulmonary nodules. To be specific, NoduleSAT132 introduced 3D CNN to Transformer-based structure and removed the pooling layer. Experiments on LUNA16 and LIDC-IDRI showed NoduleSAT132 achieved an outstanding performance on lung nodule and malignancy classification.
4.3.3 Intracranial hemorrhage classification
For RSNA intracranial hemorrhage classification, Yassine et al.130 proposed a Scopeformer to achieve the identification of different hemorrhage types according to the CT slices. Fusing CNN with Vison Transformer, Scopeformer130 employed Xception CNN for the extraction of feature maps and Vison Transformer for the establishment of long-range dependency of relevant features from different levels. When the CNN module got pretrained, the performance of Scopeformer132 could be improved further.
4.3.4 Pancreatic cancer classification
Pancreatic cancer is rare but fatal. Thus, pancreatic cancer's fatality makes it urgent for preliminary intervention while the its scarcity causes the huge health burden for general screening of whole population to have little positive effect. Therefore, considering the economic cost and complexity of single-phase noncontrast CT scan, Xia et al.131 proposed a novel model to classify the pancreatic ductal adenocarcinoma (PDAC) and other abnormalities (nonPDAC) from the other normal according to the CT image. Xia et al.131 tested their model on a data set that included 1321 patients and reached 95.2% for sensitivity and 95.8% for specificity.
4.4 Fundus or OCT
4.4.1 Retinal disease classification
Medical imaging task, unlike other tasks in CV, may not provide a large data set for the training of automatic classification. Thus, Transformer-based network, with its huge demand for large-scale training data set, may not apply to medical imaging task. To maintain the Transformer's outstanding performance and adapt it to retinal disease classification, Yu et al.86 proposed a MIL-VIT, which pretrained the Transformer model preliminarily on a fundus image data set and the fine-tuned the network for the sake of retinal disease classification. Additionally, a MIL was employed to improve the performance of the model, which was proved on two public datasets to outperform other CNN-based methods.
4.4.2 Diabetic retinopathy (DR) classification
Taking the lead in causing permanent blindness, DR can be recognized at an early stage with the help of automatic classification method, the tasks of which include both DR grading and lesion discovery. Unlike what the previous methods took, Sun et al.87 proposed to achieve the DR grading and lesion discovery simultaneously and therefore introduced a novel lesion-aware Transformer (LAT). LAT87 adopted the encoder-to-decoder structure, in which a pixel relation based encoder and a lesion filter based decoder were set. The performance of LAT137 was tested on Messidor-1, Messidor-2, and EyePACS. Figure 5 showed the structure of LAT in Wang et al.137

4.4.3 Retina lesion analysis
Compared with other images, retina OCT images bear obvious speckle noise, irregularity and vague features. To tackle these problems, Wen et al.106 proposed a novel lesion-localization convolution Transformer (LLCT), which not only classify the ophthalmic diseases, but also localize the target retina lesion region. Specifically, LLCT106 employed CNN to obtain the feature map, which was then reshaped as the input for the Transformer-based network. The gradient weight during the backward propagation was summed to get the lesion location region.
4.5 Histopathology images
4.5.1 Breast cancer classification
The image resolution and high cost for annotations have influenced the progress in digital pathology. For the pathology image classification, patch-based MIL is generally adopted, which give unified attention on each part of the images with only a small fraction being useful. Thus, Thomas et al.81 proposed a ScoreNet to reassign the computational resources according to the distribution of discriminative image regions. With a combination of local and global features, ScoreNet81 could achieve an efficient classification on target regions. Additionally, ScoreMix,81 a novel method for data augmentation, was utilized in ScoreNet.81 Validated on three breast cancer histology datasets, ScoreNet reached a state-of-the-art result.
4.5.2 Cervical cancer classification
There exist only a few public cervical cancer datasets, the quality of which were also unsatisfactory in image quality and sample distribution. Thus, Zhao et al.82 introduced the taming Transformer design to launch a novel cervical cell image generation model: T2T-ViT to improve the classification results of cervical cancer. This Tokens-to-Token Vision Transformers (T2T-ViT) model can provide balanced and sufficient cervical cancer datasets with high quality. With an encoder-to-decoder structure, T2T-ViT introduced SE-block and MultiRes-block in the encoder and SMOTE-Tomek Links82 to adjust the sample numbers and image weights of the data set.
4.5.3 Colorectal cancer classification
Chen et al.83 proposed an IL-MCAM model for the diagnosis of colorectal cancer. Unlike existing approaches focusing on end-to-end classification, IL-MCAM framework place emphasis on human-computer interaction. Fusing attention mechanism and interactive learning, IL-MCAM83 can be correspondingly divided into two stages. In the first stage, automatic learning was achieved via three Transformer-based network and CNN; in the second stage, misclassified images were rejoined to training set interactively for the promotion of performance. Experimental results on HE-NCT-CRC-100K data set demonstrated the superiority of IL-MCAM over other methods.
4.5.4 Renal cell carcinoma (RCC) classification
For papillary (p) RCC, the two subtypes: type 1 and type 2 of pRCC are similar but informative of different information about the symptom of pRCC, such as cellular and cell-layer level patterns. Considering the CNN's incapability of distinguishing these two subtypes, Gao et al.84 proposed an instance-based Vision Transformer (IViT), which utilized Transformer-based network to finish the classification of two subtypes based on representations of input images. To be specific, top-K instances were chosen to be aggregated to obtain the cellular and cell-layer information after attention mechanism.
4.5.5 Lung cancer classification
Lung cancer accounts for many deaths all over the world. For nonsmall-cell lung cancer (NSCLC), there existed two subtypes: Lung adenocarcinoma (LUAD) and lung squamous cell carcinoma (LUSC). Histology is generally used by pathologists to give the classification result of lung cancer subtype. To achieve the automatic classification of lung cancer subtypes, Guo et al.85 proposed a novel framework, which employed a pretrained vision Transformer to finish the multilabel lung cancer based on the histology images. Zheng et al.100 proposed a novel Graph-Transformer based framework for processing pathology data (GTP), which made use of morphological and spatial information in predicting the disease grade. The design of Transformer-based GTP85 is shown in Figure 6.

4.5.6 Endometrial classification
Despite the wide appearance of Transformer in whole slide image (WSI) classification, the limitation of effectiveness and efficiency, which was caused by token-wise selfattention design and positional embedding operation in a typical Transformer, handicapped the further development of WSI classification. Zheng et al.99 proposed a kernel attention Transformer (KAT), which transmitted the information tokens via a cross-attention mechanism and used a set of kernels to represent the positional anchors on the WSI. Therefore, KAT99 can balance the detail contextual information of WSI with the computational complexity.
4.5.7 Melanoma classification
It is extremely challenging to recognize the melanocytic lesion according to the pathology image. Generally, only an experienced dermatopathologist can overcome the intra- and interobserver variability and judge whether the invasive melanoma. With the digitalization of whole slide image, some automatic classification methods have emerged as the attempts to replicate the pathologists' diagnosis. Wu et al.102 proposed a novel ScATNet to obtain the multiscale representations of melanocytic skin lesions on WSI modality. Experimental results showed that ScATNet0'superiority to other WSI classification methods.
4.6 Multimodality
4.6.1 Pure Transformer-based
Bhattacharya et al.107 proposed a Student–teacher Transformer-based network, called RadioTransformer to model the radiologists' diagnosis on chest radiography. For radiologists, visual information was crucial to the classification of medical image. With an eye-gaze tracking technology, the behavior of expert can be captured. RadioTransformer107 made full use of the rich detail information for diagnosis. Specifically, RadioTransformer107 took a global-local Transformer encoder-to-decoder structure to extract both global and local information for a visual depiction of attention regions.
4.6.2 CNN-based 2D classification
It has been over a decade since CNN emerged as the dominant method for medical imaging tasks. However, as the Transformer from NLP got modified for vision tasks, the traditional mainstream CNN has been challenged by the newcomer: vison Transformer. A comprehensive comparison between CNN and vision Transformer is needed, which provokes Matsokus et al.108 to raise the question: Is it Time to Replace CNNs with Transformers for Medical Images?.108 Attempting to answer this question after a careful examine on both CNN and ViT's performances, Matsokus et al.108 set some experiments to conclude based on concrete quantitative results.
4.6.3 CNN-based 3D classification
Jang et al.111 introduced a multiplane and multislice Transformer (M3T) network to construct a three-dimension model for medical image classification. Aiming at the Alzheimer's disease, Jang et al.111 integrated CNN of both 2D and 3D with Transformer-based network to achieve the classification of Alzheimer's disease. In fact, these three parts were respectively responsible for different targets: 2D and 3D CNN extracted the local features based on 2D and 3D input images while Transformer-based network developed a long-range relationship on CNN output.
4.7 Other modalities
4.7.1 Dermoscopy
As one of the deadliest diseases all over the world, skin cancer takes thousands of lives each year. To provide intervention for skin cancer at an early stage, the deep learning method is used for the classification and diagnosis of skin cancer. However, the automatic classification of skin cancer is posed with some certain challenges: lower accuracy, deficit of labeled data and poor generalization. For these challenges, Aladhadh et al.118 proposed a medical vision transformer (MVT), a two-stage framework designed to introduce the attention mechanism for skin cancer classification. Nakai et al.119 proposed a novel bottleneck Transformer network (DPE-BoTNeT) by joining convolution network with the Transformer design to supplement the initial network with the capability of extracting global dependency and interpretating the positional information.
4.7.2 US
For breast cancer imaging, US imaging can be extremely helpful owing to its low cost and safety. Among the automatic classification methods based on US image, CNNs have emerged as the most prevalent structure. However, the limitation of CNN in receptive field lead to the loss of global context information. Thus, Gheflati et al.104 introduced vision Transformer into the US-based breast cancer classification. According to the classification accuracy and area under the curve (AUC) metrics on US data set, this method outperformed the state-of-the-art CNNs.
4.7.3 Photo
One out of three diabetic patients may be troubled with diabetic foot ulcers (DFU). With the recent increase in DFU, it is urgent to diagnose the DFU at an early stage before ischemia and infection appears as DFU deteriorates. Qayyum et al.105 introduced a novel network combining both CNN and Transformer to achieve the diagnosis of DFU. Fine-tuning the CNN and Transformer structure on DFUC-21 data set, Qayyum et al.105 chose two of the five Transformers for the feature extraction and finished the DFU detection.
4.7.4 Microscopy
As one of the most dangerous diseases that mosquito bites may arouse, malaria can cause serious consequences, even death. To recognize the existence of malaria timely, microscopy is used to examine whether malaria parasites are present in the blood sample. However, this method consumes much time and effort, which may not apply to a large-scale examine of malaria. Thus, Islam et al.112 proposed a novel method based on multiheaded attention mechanism to diagnose the malaria parasite. This model reached 96.41%, 96.99%, 95.88%, 96.44%, and 99.11% for accuracy, precision, recall, f1-score, and AUC score on testing data set. Among lymph diseases, acute lymphocytic leukemia (ALL) is a cancer with high fatality for both adults and children. To give a timely and accurate diagnosis of ALL, Jiang et al.113 proposed a ViT-CNN ensemble model to find cancer cell images from the other normal cell images. Combining both CNN and vision Transformer, ViT-CNN113 utilized CNN to extract rich features from the input images and Transformer to give the classification result. Experimental results on test set demonstrated that ViT-CNN reached 99.03% for accuracy in terms of diagnosis of ALL.
4.7.5 Cytopathology
As the fourth most common female cancer all over the world, cervical cancer can be diagnosed via cervical cytopathology. The automatic classification of cervical cancer classification based on cytopathology images has correspondingly developed considering the manual screening's time expenses and probable errors. Thus, Liu et al.120 proposed a novel CVM-Cervix to give the cervical cell classification with high speed and accuracy. CVM-Cervix set a CNN module and a vision Transformer module respectively for the extraction of local and global features. Eventually, the classification result was given fusing both local and global feature via a Multilayer Perceptron module.120
4.7.6 Colposcopy
Human papilloma virus (HPV) may cause both the cervical lesions and cervical cancer. As the symptom deteriorates, the precancerous lesion can be classified into three stages: CIN1, CIN2, and CIN3. The classification of these three stages can help the patient with the treatment of cervical cancer. Therefore, Li et al.121 proposed a novel method, which fused both the vision Transformer and DenseNet to classify the subtype of the cervical cancer. Li et al.121 employed the fivefold cross-validation methods to train and fuse the vision Transformer and DenseNet161 model. Experimental results showed that this model reached 68% for accuracy rate.
5 MEDICAL IMAGE DETECTION
Unlike the segmentation and classification, medical image detection place emphasis on detecting the occurrence of a specific malady. In fact, considering the conflict between the limited medical resource and the expanding medical requirement, the automatic medical image detection may be potentially taken into consideration as a powerful tool for disease screening. The automation of medical image detection takes advantage of artificial intelligence, which spared some of doctors so that they can exploit their talent in dealing with more serious diseases. The papers on medical image detection based on Transformer are shown in Table 3.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| RDFNet138 | Image | Tooth | Caries |
| MA139 | Fundus | Eye | Microaneurysm |
| AG-CNN140 | Fundus | Eye | Glaucoma |
| TIA-Net141 | Fundus | Eye | Glaucoma |
| Koushik142 | X-ray | Chest | COVID-19 |
| Duong143 | X-ray | Chest | Tuberculosis |
| CLAM144 | WSI | Multiorgan | None |
| MCAT145 | WSI | Multiorgan | Cancer |
| Gheflati100 | US | Breast | Breast cancer |
| UTRAD146 | Multimodality | UNet-based | 2D |
| Tomita147 | Micro | Esophagus | Esophagus tissue |
| DETR148 | MRI | Lymph | Lymph node |
| COTR149 | Colonos | Colorectal | Polyp |
| Liu150 | Colonos | Colorectal | Polyp |
| Rahhal151 | CT + X-ray | Chest | COVID-19 |
| TRACE152 | CT | Kidney | CKD |
| SATr153 | CT | Lesion | None |
| STCovidNet137 | CT | Lung | COVID-19 |
| Chuang154 | CT | Lung | Lung nodule |
| Chest X142 | CT | Lung | COVID-19 |
| POCFormer155 | CT | Lung | COVID-19 |
| SwinFpn156 | CT | Multiorgan | None |
| Effinet143 | CT | Lung | Tuberculosis |
| Islam157 | CT | Kidney | Cyst, stone, tumor |
| Covid-Trans93 | CT | Lung | COVID-19 |
| AANet158 | CT | Lung | COVID-19 |
| Pesce159 | CT | Lung | Lung nodule |
| TR-Net160 | CCTA | Artery | Coronary artery stenosis |
| VIEW-DISENTANGLED161 | MRI | Brain | Brain lesion |
| Name | Modality | Organ/Method | Disease/Dimension |
| E-DSSR162 | Endoscopy | Surgical | Dynamic surgical scene |
| MIST-net163 | X-ray | Cardiac | Image quality improvement |
| CNN-Transformer164 | X-ray | Bone | Long bone |
| SSTrans-3D165 | SPECT | Cardiac | 3D reconstruction |
| ADVIT166 | PET | Brain | Alzheimer's Disease |
| TransEM167 | PET | Brain | Image quality improvement |
| SMIR168 | MRI | Brain | Super-resolution |
| SLATER169 | MRI | Multiorgan | Unsupervised reconstruction |
| ReconFormer170 | MRI | Multiorgan | Accelerated reconstruction |
| DSFormer171 | MRI | Multiorgan | Accelerated reconstruction |
| McMRSR172 | MRI | Multiorgan | Super-resolution |
| PKT173 | MRI | Multiorgan | Undersample reconstruction |
| HUMUS-Net174 | MRI | Multiorgan | Accelerated reconstruction |
| Kspace-Trans175 | MRI | Multiorgan | Accelerated reconstruction |
| SVoRT176 | MRI | Brain | Fetal brain |
| TITLE177 | MRI | Multiorgan | Accelerated reconstruction |
| T2Net178 | MRI | Multiorgan | Joint |
| MTrans179 | MRI | Multiorgan | Accelerated reconstruction |
| SRT180 | MRI | Brain | 2D to 3D |
| FedGIMP181 | MRI | Multiorgan | accelerated reconstruction |
| ASMT182 | MRI | Brain | Super-resolution |
| SAT-net183 | MRI | Cartilage | Acceleration + image quality |
| McSTRA184 | MRI | Multiorgan | Accelerated reconstruction |
| KangLin185 | MRI | Multiorgan | Acceleration reconstruction |
| ASFT182 | MRI | Brain | Super-resolution |
| TranSMS186 | MPI | Multiorgan | Super-resolution |
| CTformer187 | LDCT | Multiorgan | Denoising |
| Liu188 | LDCT | Multiorgan | Degradation |
| TransCT189 | LDCT | Multiorgan | Enhancement |
| TED-Net190 | LDCT | Liver | Denoising |
| transGAN-SDAM191 | l-PET | Brain | Image quality improvement |
| Wu192 | CT | Multiorgan | Image quality improvement |
| DuDoTrans193 | CT | Multiorgan | Image quality improvement |
| TVSRN194 | CT | Multiorgan | Super-resolution |
| Sizikova195 | CT | Lung | 3D Shape Induction |
| Eformer196 | CT | Multiorgan | Denoising |
5.1 X-ray or radiographic images
5.1.1 COVID-19 detection
For COVID-19, the CT-based or X-ray-based detection involves the medical professionals, which may restrict the speed and efficiency of detection. Thus, Krishnan et al.142 attempted to ease this problem by proposing an automatic method for detecting the COVID-19 according to the CT or X-ray images. Krishnan et al.142 fine-tuned a vision Transformer to fit the need of COVID-19 detection task on CT or X-ray images and reached a state-of-the-art performance in terms of accuracy, precision, recall and F1 score. Rahhal et al.151 proposed to perform the Coronavirus detection based on the CT and X-ray images. Specifically, Rahhal et al.151 took a vision Transformer as the backbone and Siamese encoder for feature extraction. After a patch division, input images were processed in the encoder. After the evaluation on CT and X-ray datasets, this framework outperformed other methods in five indicators.
5.2 MRI
5.2.1 Lymph node (LN) detection
For researchers who attempt to assess the lymphoproliferative disease, the LN need to be identified in T2 MRI images. Diverse appearances of lymph nodes made it difficult for radiologists to pick out the LNs according to T2 MRI image. Therefore, Mathai et al.148 proposed the DEtection Transformer (DETR) framework for the localization of lymph nodes. A bounding box fusion technique was adopted in DETR148 to reduce the false-positive rate. Experimental results showed that DETR148 reached 65.41% for precision and 91.66% for sensitivity.
5.2.2 Brain lesion detection
For the location of small brain lesions, the 3D context synthesis conflicts with the computational cost. Therefore, Li et al.161 proposed a view-disentangled Transformer for MRI feature extraction to accurately detect the tumor. Taking a Transformer backbone with view-disentangled Transformer module, this framework modelled a long-range dependency within the different positions. Multiple 2D slice features were extracted and enhanced in this view-disentangled Transformer module.
5.3 CT
5.3.1 Lung nodule detection
In fact, the earlier the lung nodules get detected, the more likely it is for lung cancer patients to survive. However, the varied appearance and location of lung nodules make it difficult for automatic computer-aided detection of lung nodule. To diminish the high false-positive rate of nodule detection, Niu et al.154 proposed a 3D Transformer framework to achieve lung nodule detection. Specifically, the input CT images got sliced into a nonoverlap sequence, each unit of which was analyzed with selfattention mechanism. Besides, Niu et al.154 chose a region-based contrastive method to train the model to promote the training result.
5.3.2 Tuberculosis detection
For the early detection and analysis of tuberculosis, artificial intelligence technology can be beneficial to the automatic recognition of tuberculosis based on the chest X-ray images, which have been proved on the experimental results on some small chest X-ray data set. Duong et al.143 aimed to propose a novel framework, which maintained the encouraging performance on large datasets. Specifically, Duong et al.143 fused three networks for the detection of tuberculosis: modified EfficientNet, modified vision Transformer and modified hybrid model.
5.3.3 Chronic kidney disease (CKD) detection
The shortage of the positive patients and other risk factors have handicapped the development of CKD automatic detection. Wang et al.152 proposed the TRACE (Transformer-RNN Autoencoder-enhanced CKD Detector), which achieved the end-to-end CKD prediction. TRACE adopted an autoencoder with both attention mechanism and RNN unit. Consequently, TRACE152 can analyze the medical history information of the patients comprehensively. Experimental results on a data set based on real-world medical information showed that TRACE152 performed a state-of-the-art task.
5.3.4 Cyst, stone, tumor detection
Although the renal failure, with its severe consequence, has aroused much public attention, few attempts to apply artificial intelligence to diagnose kidney diseases. Setting kidney stones, cysts, and tumors, the three major renal diseases, as the target, Islam et al.157 launched six models, such as EANet, CCT and Swin Transformer. After a comprehensive comparison, the framework based on Swin Transformer have shown to be outperform other methods as for accuracy, F1 score, precision and recall.
5.3.5 Universal lesion detection (ULD)
For ULD, most methods achieved the detection task by extracting 3D contextual information combining a series of adjacent CT slice Slice s. However, these operations affect the globality of feature representation. Li et al. proposed a novel Slice Attention Transformer (SATr), which was joined in a convolution-based structure. This design obtained both a long-range dependency and a local feature extraction, which was validated by the experimental results on testing data set.
5.4 Fundus or OCT
5.4.1 Microaneurysm detection
The size and complexity of retinal fundus makes it difficult to detect the Microaneurysms, which are the early sign of DR. Zhang et al.139 proposed a novel detection model. To be specific, Zhang et al.139 used equalization operations to improve the fundus image quality. Afterward, attention mechanism was adopted to obtain the preliminary features of retinal fundus images. Besides, Zhang et al.139 analyzed the association between the microaneurysm and blood vessel from a spatial perspective. Experimental results on IDRiD_VOC data set showed this method outperformed other attempts in terms of average accuracy and sensitivity.
5.4.2 Glaucoma detection
Associated with vision deprivation, glaucoma was targeted by many automatic detection researchers. But the high redundancy in fundus image influenced the further accuracy improvement of glaucoma detection. Therefore, Li et al.140 proposed AG-CNN, a novel framework fusing convolution operation with attention mechanism. Li et al.140 prepared a large glaucoma database with 11,760 fundus images. For AG-CNN, Li et al.140 designed three subnets, which were respectively responsible for attention prediction, pathological area localization and glaucoma classification.
5.5 Histopathology image
5.5.1 Multiorgan detection
Most computational pathology methods based on deep learning need the manual labelling of many whole slide images. To get rid of the burden of manual efforts, Lu et al.144 proposed Clustering-constrained Attention Multiple instance learning (CLAM) to achieve the automatic multiorgan detection with both efficiency and interpretability. CLAM144 employed the attention mechanism to find out discriminated sub-regions, which were then clustered to refine the target region.
5.5.2 Cancer detection
It is of great difficulty to predict the survival outcome based on the whole slide images (WSIs) of patients. Both computational complexity and data heterogeneity gap pose a challenge for attempts to treat WSIs as the bags for MIL. Therefore, Chen et al.145 proposed a multimodal co-attention transformer (MCAT) framework to solve the above problems. Mapping the WSI features into an embedding space, MCAT145 assimilated how word embeddings picked salient objects. The spatial complexity got specifically reduced when extracting the WSI-based features. Experimental results on five cancer data set demonstrated the MCAT's superior performance.
5.6 Other modalities
5.6.1 Coronary CT angiography (CCTA)
Considering the serious consequence of coronary artery disease (CAD), the corresponding automatic diagnosis is of great importance. To overcome the structural complexity, which has troubled the modelling of coronary artery, Ma et al.160 proposed a Transformer network (TR-Net) to detect the coronary artery stenosis based on the CCTA. TR-Net integrated Transformer-based encoder with convolutional modules to take in the advantages of both. Consequently, TR-Net analyzed the cross-image information and find out the stenosis.
5.6.2 Image-based
Although the dental caries is quite widespread, few studies place emphasis on caries detection. Thus, Jiang et al.138 proposed a RDFNet, which was suitable for portable caries detection. Utilizing the attention mechanism to extract the features from the input images, RDFNet adopted the FReLU activation function to accelerate the caries detection so that it can fit the condition of portable devices. Experimental results on datasets showed that RDFNet outperformed other methods in terms of accuracy and speed.
5.6.3 Dermoscopy
In many vision tasks, such as object detection, image classification and semantic segmentation, Transformer-based models have proved to outperform the CNN-based models. However, Transformer-based network fail to maintain its superior performance on finding out the out-of-distribution samples. Thus, Li et al.197 evaluated four Transformer on two open-sourced medical image datasets. The result showed that the Transformer-based attempts on out-of-distribution were still insufficient.
5.6.4 Microscopy
Tomita et al.147 proposed a novel method for detection of Barrett esophagus (BE) and esophageal adenocarcinoma. To be specific, this method made use of annotations from the tissue level based on the histological patterns on microscopy images. Both convolution operations and attention-mechanism were used in this framework. The testing set for this model include 123 images divided into four classes: normal, BE-no-dysplasia, BE-with-dysplasia, and adenocarcinoma.
5.6.5 Colonoscopy
Colonoscopy is widely adopted for the diagnosis of polyp lesions, which may evolve into the second most mortal cancer: colorectal cancer. To spare the endoscopists from the huge manual efforts on screening out the polyp, Shen et al.149 proposed an end-to-end polyp detection model, named convolution in Transformer (COTR). Inspired by detection Transformer (DETR), COTR149 utilized CNN for the feature extraction, Transformer encoders to encode and recalibrate the features and Transformer decoders to query the object. Experimented on two public polyp datasets, COTR149 outperformed other state-of-the-art methods. Combining the attention mechanism with the convolution layers, Liu et al.150 proposed a novel framework for the accurate polyp detection. Liu et al.150 used a traditional CNN backbone to give a preliminary 2D representation, the result of which got passed to Transformer encoder after a flattening and positional encoding. After the Transformer decoder, a feedforward network (FFN) obtained the output embedding of Transformer decoder to give the prediction of detection.
5.6.6 Multimodality
Chen et al.146 proposed U-TRansformer based Anomaly Detection framework (UTRAD) to overcome the unstable training and ununified judgement for feature distribution evaluation. UTRAD146 employed attention-based autoencoders to describe the pretrained features. Setting not the raw images but the feature distribution to reconstruct, UTRAD146 stabilized the training process and improved the detection accuracy. A multiscale pyramidal hierarchy was adopted in UTRAD146 for the detection of anomalies. Tested on retinal, brain, head data set, UTRAD146 outperformed other methods.
6 MEDICAL IMAGE RECONSTRUCTION
In clinical practice, there may exists an image quality deficit in the obtained medical images. After all, the medical images, unlike the computer simulation, are collected through some medical equipment, the result of which may be influenced by the realistic constraint and accidental factors. Besides, sometimes for the diminishing of side effect, some technology may sacrifice the image quality, namely low-dose computed tomography (LDCT). For low-quality medical images, some researchers have raised their solutions to improvement of the image quality through the image construction Transformer-based AI models. Their trials are collected in Table 4.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| E-DSSR162 | Endoscopy | Surgical | Dynamic surgical scene |
| MIST-net163 | X-ray | Cardiac | Image quality improvement |
| CNN-Transformer164 | X-ray | Bone | Long bone |
| SSTrans-3D165 | SPECT | Cardiac | 3D reconstruction |
| ADVIT166 | PET | Brain | Alzheimer's Disease |
| TransEM167 | PET | Brain | Image quality improvement |
| SMIR168 | MRI | Brain | Super-resolution |
| SLATER169 | MRI | Multiorgan | Unsupervised reconstruction |
| ReconFormer170 | MRI | Multiorgan | Accelerated reconstruction |
| DSFormer171 | MRI | Multiorgan | Accelerated reconstruction |
| McMRSR172 | MRI | Multiorgan | Super-resolution |
| PKT173 | MRI | Multiorgan | Undersample reconstruction |
| HUMUS-Net174 | MRI | Multiorgan | Accelerated reconstruction |
| Kspace-Trans175 | MRI | Multiorgan | Accelerated reconstruction |
| SVoRT176 | MRI | Brain | Fetal brain |
| TITLE177 | MRI | Multiorgan | Accelerated reconstruction |
| T2Net178 | MRI | Multiorgan | Joint |
| MTrans179 | MRI | Multiorgan | Accelerated reconstruction |
| SRT180 | MRI | Brain | 2D to 3D |
| FedGIMP181 | MRI | Multiorgan | Accelerated reconstruction |
| ASMT182 | MRI | Brain | Super-resolution |
| SAT-net183 | MRI | Cartilage | Acceleration + image quality |
| McSTRA184 | MRI | Multiorgan | Accelerated reconstruction |
| KangLin185 | MRI | Multiorgan | Acceleration reconstruction |
| ASFT182 | MRI | Brain | Super-resolution |
| TranSMS186 | MPI | Multiorgan | Super-resolution |
| CTformer187 | LDCT | Multiorgan | Denoising |
| Liu188 | LDCT | Multiorgan | Degradation |
| TransCT189 | LDCT | Multiorgan | Enhancement |
| TED-Net190 | LDCT | Liver | Denoising |
| transGAN-SDAM191 | l-PET | Brain | Image quality improvement |
| Wu192 | CT | Multiorgan | Image quality improvement |
| DuDoTrans193 | CT | Multiorgan | Image quality improvement |
| TVSRN194 | CT | Multiorgan | Super-resolution |
| Sizikova195 | CT | Lung | 3D shape induction |
| Eformer196 | CT | Multiorgan | Denoising |
6.1 X-ray or radiography
6.1.1 Cardiac reconstruction
Decreasing projection views to lower X-ray radiation dose usually causes severe streak artifacts, especially for cardiac X-ray images. To improve image quality from sparse-view data, a multidomain integrative swin transformer network (MIST-net) was proposed.163 MIST-net fused lavish domain features from data, residual-data, image, and residual-image adopting flexible network architectures, where residual-data and residual-image subnetwork was utilized as data consistency module to eliminate interpolation and reconstruction errors. A trainable edge enhancement filter was constructed to detect and protect image edges for high-quality reconstruction of image global features. According to the experiment results on numerical and real cardiac clinical datasets with 48-views, MIST-net improved the image quality with more small features and sharp edges than other competitors.
6.1.2 Long bone reconstruction
For conventional 3D imaging technologies like CT and MRI, their high radiation dose and the requirements for lying postures could influence the accuracy of reconstructed bones and diagnosis results to a large extent. Besides, methods based on bone contours tend to be dependent on prior knowledge with precise bone segmentation methods to be rare. To address these issues, a novel model based on multiviews of contours was proposed in Ge et al.164 for bone reconstruction and a hybrid CNN-Transformer approach for bone contours segmentation. When tested on 301 bone X-ray images and by considering p-value < 0.05, the proposed Trans-Detseg approach performed a satisfactory task with Dice Similarity Coefficient of 0.949 and Hausdorff Distance of 26.17 than three state-of-the-art models. Figure 7 showed the pipeline of CNN-Transformer for medical image reconstruction in Ge et al.164

6.2 MRI
6.2.1 Accelerated reconstruction
With some under-sampled and noisy input images, deep learning can reconstruct the ideal MRI images. Among these methods, both CNN-based networks and Transformer-based model bear its own advantages and drawbacks.170, 171, 174, 175, 177, 179, 181, 184 made corresponding adjustments to some part of MRI, including k-space and sampling to promote the speed of MRI. The scan of MRI demands much time to generate the complete K-space matrices. To reduce the scan time to a large extent, Liu et al.177 proposed the transformer involved trajectory learning (TITLE), a reinforcement learning framework based on Transformer. TITLE177 associated the Q-value in reinforcement learning with the reconstruction image quality of MRI. Here, TITLE177 predicted the Q-value based on phase-indicator vectors and K-space matrices. With inverse Fourier transform operation to be widely used, TITLE177 eventually achieved an efficient reconstruction of MRI image.
6.2.2 Cartilage reconstruction
Despite a high image quality, MRI requires a demanding time expense for data acquisition. The introduction of convolution neural modules does make contribution to the acceleration of MRI yet brings a limited receptive field. Thus, Wu et al.183 proposed a SAT-net to achieve the promotion on both image fidelity and acceleration. With an attention mechanism for long-range relationship, Wu et al.183 maintained the residual convolutional modules in SAT-net. Applied on cartilage MRI, SAT-net183 got trained on 336 3D images and got tested on 24 images.
6.2.3 Super-resolution (SR)
Compressed sensing, a traditional method for reconstruction, was generally adopted for the down-sampling MRI SR. To overcome the time expense of compressed sensing, Yan et al.168 proposed to introduce Swin Transformer to MRI SR of brain, called as SMIR. To be specific, SMIR168 were divided into two modules: a multilevel feature extraction module and a reconstruction module. To ensure the details of reconstruction, SMIR168 attend to both the frequency domain and spatial domain losses.
6.2.4 2D-to-3D reconstruction
For 3D construction in invasive surgeries, the convolutional-based frameworks are too complex in structure while the GAN-based networks are hard to train. Thus, Hu et al. proposed the shape reconstruction transformer (SRT) to fuse the selfattention mechanism with generative design to achieve a 3D brain construction with both high speed and accuracy. Hu et al. used point clouds to give a 3D description based on the 2D input images. With both a qualitative demonstration and a quantitative experiment, SRT showed a superior performance compared with other state-of-the-art methods.
6.2.5 Unsupervised reconstruction
Recent studies on supervised reconstruction methods integrated the image operators with the untrained MRI priors for the sake of supervision requirement reduction. Korkmaz et al. proposed a zero-Shot Learned Adversarial TransformER (SLATER) to fuse the attention mechanism with the adversarial network for the unsupervised MRI reconstruction. The pretraining period prepared the high-quality MRI prior for the inference period, in which SLATER169 achieved a zero-show reconstruction via the imaging operator. Experimental results on brain MRI datasets showed SLATER9'state-of-the-art performance.
6.2.6 Undersampling reconstruction
Inspired by the Transformer network to deal with long-range dependencies in sequence transduction tasks,173 proposed to rearrange the radial spokes to sequential data according to the chronological order of acquisition and introduce the Transformer network to give a prediction of unacquired radial spokes from the acquired data. The authors proposed novel data augmentation methods called projection-based K-space transformer (PBKT) to generate a large amount of training data from a limited number of subjects, which can, furthermore, be applied to different anatomical structures. Experimental results show PBKE achieve a superior performance compared to state-of-the-art deep neural networks.
6.3 CT
6.3.1 3D shape induction
Sizikova et al. propose an approach for training an automatic chest CT reconstruction algorithm with X-ray only.195 The authors augment existing model training on DRR-generated X-ray and CT pairs with a shape induction loss, which make the model capable of learning from only real input X-rays. This approach allows grasping the variability of real X-ray images and directly incorporating it into the training of the CT generation model. The ability to obtain rich distributions from real X-rays is particularly essential for practical applications where the network is required to adapt to different imaging sensor types and diverse patient anatomy.
6.3.2 Image quality improvement
Using CT reconstruction from X-ray is useful for clinical diagnosis, iodine radiation during the imaging process induces irreversible injury, thereby leading researchers to focus on sparse-view CT reconstruction by recovering a high-quality CT image from a sparse set of sinogram views. Iterative models are presented to alleviate the appeared artifacts in sparse view CT images though a rather expensive computation cost. To overcome the above-mentioned issues, a dual-domain Transformer (DuDoTrans) was proposed in Wang et al.193 to simultaneously restore informative sinograms by modelling the long-range dependency and achieve the reconstruction task of CT image with both the enhanced and raw sinograms. As reported in the work, reconstruction performance on the NIH-AAPM data set and COVID-19 data set experimentally confirms the effectiveness and generalizability of DuDoTrans with fewer involved parameters. According to the extensive experiments, DuDoTrans also demonstrate its robustness with different noise-level scenarios for sparse-view CT reconstruction.
6.3.3 SR
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used owing to short acquisition time and lower storage cost. However, the coarse resolution may bring difficulties in medical image diagnosis by either physicians or computer-aided diagnosis algorithms. In fact, deep learning-based volumetric SR methods have risen as feasible ways to improve resolution, with CNN at their core. Despite recent progress, these methods are restricted by inherent properties of convolution operators, which ignore content relevance and fail to effectively model long-range dependencies. Furthermore, most of the existing methods adopt pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a basic degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the unsatisfactory performance of these methods in practice. To address the above issues, the first public real-paired data set RPLHR-CT was proposed in Yu et al.194 as a benchmark for volumetric SR. The baseline results are provided by re-implementing four state-of-the-art CNN based methods. To get rid of the inherent shortcoming of CNN, the authors propose a Transformer volumetric SR network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. As the first research to use a pure Transformer for CT volumetric SR, TVSRN reached the experimental results, which show that TVSRN significantly outperforms all baselines on both PSNR and SSIM additionally with a better trade-off between the image quality, the number of parameters, and the running time.
6.3.4 Denoising
Image denoising is a long-standing topic in CV and processing community. For medical image field, compared to general images in ImageNet, there is a lot of prior knowledge that can be leveraged to enhance our model. In Luthra et al.,196 the authors present an edge-enhancement based model, that is, Eformer, a novel architecture that constructs an encoder-decoder network using Transformer blocks for medical image denoising. Nonoverlapping window-based selfattention is utilized in the Transformer block that reduces computational burden. This work further incorporates learnable Sobel-Feldman operators to enhance edges in the image and explore an effective way to concatenate them in the intermediate layers of Eformer. Eformer undergoes the experimental analysis, which is conducted by comparing deterministic learning and residual learning for the task of medical image denoising. In addition, Eformer also gets evaluated on the AAPM-Mayo Clinic Low-Dose CT Grand Challenge Data set and receives the state-of-the-art performance, that is, 43.487 PSNR, 0.0067 RMSE, and 0.9861 SSIM.
6.4 LDCT
6.4.1 Denoising
LDCT is widely applied in clinical practice. However, in comparison with normal dose CT, in the LDCT images, there exist stronger noise and more artifacts which are obstacles for practical applications. In the past few years, convolution-based end-to-end deep learning methods have been prevalently used for LDCT image denoising. Recently, Transformer has demonstrated superior performance over convolution with more feature interactions. Yet its applications in LDCT denoising have not been comprehensively cultivated. In Wang et al.,190 the authors propose a convolution-free T2T vision Transformer-based Encoder-decoder Dilation network (TED-net) to enrich the family of LDCT denoising algorithms. The model is irrelevant to convolution blocks and consists of a symmetric encoder-decoder block based on sole Transformer. The model is evaluated on the AAPM-Mayo clinic LDCT Grand Challenge data set and achieves the experimental results, which shows that the proposed model outperforms other state-of-the-art models with the highest SSIM value and smallest RMSE value. As for the continual improvement of this model, it can be further slimmed with a more powerful tokenization without downgrading of images.
6.4.2 Multiorgan reconstruction
Compared to the normal dose CT (NDCT), LDCT images are subjected to severe noise and artifacts, which left much to be done for deep learning-based reconstruction methods. Recently in many studies, vision Transformers have shown superior feature representation ability over CNNs. However, unlike CNNs, the potential of vision Transformers in LDCT denoising was far from fully explored so far. To fill this gap, the authors in Wang et al.190 proposed a Convolution-free Token2Token Dilated Vision Transformer, called CTformer for low-dose CT denoising. The CTformer uses a more powerful token rearrangement to encompass local contextual information to replace the role that convolution operation plays. It also dilates and shifts feature maps to capture longer-range interaction. The authors interpret the CTformer by statically inspecting patterns of its internal attention maps and dynamically tracing the hierarchical attention flow with an explanatory graph. Besides, the authors also introduce an overlapped inference mechanism so as to effectively eliminate the boundary artifacts that are common for encoder-decoder-based denoising models. Experimental results on Mayo LDCT data set prove that the CTformer outperforms the state-of-the-art denoising methods with a low computation overhead.
6.4.3 Degradation
Liu et al.188 proposed a weakly supervised method to learn the degradation of low-dose CT from unpaired low-dose and normal-dose CT images. To be specific, low-dose CT and normal-dose images were fed into one shared flow-based model and projected to the latent space. Then, the degradation between low-dose and normal-dose images was modeled in the latent space. Finally, the authors train the model by minimizing the negative log-likelihood loss with no requirement of paired training data. It should be maintained that the authors validated the effectiveness of the generated image pairs on a classic CNN, REDCNN, and a novel Transformer-based model, TransCT. The proposed method reached 24.43 dB for mean PSNR, 0.785 for mean SSIM on an abdomen CT data set, and 33.88 dB for mean PSNR, 0.797 for mean SSIM on a chest CT data set, which outperformed other advanced CT denoising methods, the same network trained by CycleGAN-generated data, and a novel transfer learning method.
6.4.4 Enhancement
Inspired by the internal similarity of the LDCT images, the authors in Zhang et al.189 present a Transformer-based neural network for LDCT, which can explore large-range dependencies between LDCT pixels. To ease the impact of noise on high-frequency texture recovery, the authors employ a Transformer encoder to further excavate the low-frequency part of the latent texture features and then exploit these texture features to restore the high-frequency features from noisy high-frequency parts of LDCT image. The final high-quality LDCT image can be piece-wise reconstructed with the incorporation of low-frequency content and high-frequency features. Extensive experiments on Mayo LDCT data set show that TransCT produces superior results and outperforms other methods.
6.5 Other modalities
6.5.1 Magnetic particle imaging (MPI)
MPI is a recent modality that provides exceptional contrast for magnetic nanoparticles (MNP) at high spatio-temporal resolution. A common procedure in MPI starts with a calibration scan to measure the system matrix (SM), the result of which can be offered to setup an inverse problem to reconstruct images of the particle distribution during subsequent scans. This calibration enables the reconstruction to be sensitive to various system imperfections. Yet time-consuming SM measurements have to be repeated under notable drifts or changes in system properties. Gungor et al.186 introduce a novel deep learning approach for accelerated MPI calibration based on Transformers for SM super-resolution (TranSMS). To be specific, low-resolution SM measurements are performed through large MNP samples for improved signal-to-noise ratio efficiency, and the high-resolution SM is super-resolved via a model-based deep network. TranSMS leverages a vision Transformer module to fulfill the task of capturing contextual relationships in low-resolution input images, a dense convolutional module for the localization of high-resolution image features, and a data-consistency module to ensure consistency to measurements. Tested on both simulated and experimental data, the results indicate that TranSMS achieves significantly improved SM recovery and image reconstruction in MPI, while enabling acceleration up to 64-fold during two-dimensional calibration.
6.5.2 Positron emission tomography image (PET)
Xing et al. proposed a ViT-based architecture called ADVIT.166 A new model trained on multimodalities of Positron Emission Tomography images (PET-AV45 and PETFDG) for Alzheimer's Disease (AD) diagnosis was introduced. Unlike the conventional methods using multimodal 3D/2D CNN architecture, ADVIT design replaces the CNN by ViT. Considering the high computation cost of 3D images, ADVIT first employ a 3D-to-2D operation to project the 3D PET images into 2D fusion images. Then, it forwards the fused multimodal 2D images to a parallel ViT model for feature extraction, followed by classification for AD diagnosis. For evaluation, PET images from ADNI were used. The proposed model outperforms several strong baseline models in our experiments and achieves 0.91 accuracy and 0.95 AUC.
6.5.3 Endoscopy
Long et al.162 proposed E-DSSR, which is an efficient reconstruction pipeline for highly dynamic surgical scenes that runs at 28 fps. Specifically, the authors design a Transformer-based stereoscopic depth perception for efficient depth estimation and a lightweight tool segmentor to handle tool occlusion. Besides, E-DSSR adopts a dynamic reconstruction algorithm which can estimate the tissue deformation and camera movement, and aggregate the information over time specifically for surgical scene reconstruction. When evaluating the proposed pipeline on two datasets, the public Hamlyn Centre Endoscopic Video Data set and in-house DaVinci robotic surgery data set, the results suggest that E-DSSR can recover the scene obstructed by the surgical tool and deal with the movement of camera in realistic surgical scenarios effectively at real-time speed.
7 REPORT GENERATION
For doctors with rich medical knowledge and abundant experience, one of the most time-consuming task may be writing the diagnosis report. In fact, the writing of medical report, including the radio report, involve medical knowledge but little creativity. With the rapid development of Artificial Intelligence, this medical task may be assigned to automatic report generation AI model. Despite many existing difficulties of report generation, the developing of a report generation framework may save much time and effort of the doctors from the writing reports. Table 5 gives a brief collection of the Transformer-based report generation methods.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| MengYaXu198 | Surgical | None | None |
| CIDA199 | Surgical | None | None |
| Zhang200 | Surgical | None | None |
| PPKED201 | Radio | None | None |
| VTI202 | Radio | None | None |
| CMN203 | Radio | None | None |
| ASGK204 | Radio | None | None |
| yixiwang205 | Radio | None | None |
| RadBERT206 | Radio | None | None |
| CDGPT2207 | Radio | None | None |
| fullTrans208 | Radio | None | None |
| Jia209 | Radio | None | Rare disease |
| Farhad210 | Radio | None | None |
| RTMIC211 | Radio | None | None |
| Miura212 | Radio | None | None |
| Chen213 | Radio | None | None |
| KGAE214 | Medical | None | None |
| MedSkip215 | Medical | None | None |
| Park216 | Medical | None | None |
| HoangTN217 | X-ray | None | None |
| RATCHET218 | X-ray | Chest | None |
| AlignTransformer219 | X-ray | None | None |
| KERP220 | X-ray | None | None |
| Yan221 | X-ray | None | None |
| CEDT222 | X-ray | None | None |
7.1 Radio report
If the radiology report can be generated automatically as the radio examine finishes, the radiologists can escape from the tiring report writing and the possible mistakes in diagnosis. Considering the textual property of the radio report, the automatic generation of radio report posed a challenge for the deep learning models.201-203, 205-207, 212, 213 aimed to assist the radiologists in radio report generation. Najdenkoska et al.202 proposed the variational topic inference framework (VTI) to overcome the diversity of radiologist writing style. VTI202 prepared a topic set, in which different topics serve as the guidance for the sentence arrangement in the report. Experimental results on test results showed that VTI202 performed a state-of-the-art task in automatic radio report generation. Wang et al.205 proposed to give a quantitative measurement of the uncertainty, whether visual or textual, to promote the quality of generated reports. Integrating the information of different modal, Wang et al.205 analyzed the uncertainty both sentence-to-sentence and as a whole. Experimental results on two public datasets showed that this model outperformed other methods.
7.1.1 Rare disease report
Despite many previous attempts for the cross-modal radiology report generation, little attention has been paid to rare disease report generation. In fact, the useless pixel redundancy and multimodal decoding failure made handicapped the development of report generation. Thus, Jia et al.209 proposed TransGen, a Transformer-based framework designed for the automatic generation of rare disease report. TransGen209 utilized a semantic-aware visual learning (SVL) module for the target region recognition and a memory augmented semantic enhancement (MASE) module to absorb the historical report sentences to boost a better report generation.
7.2 Medical report
Owing to the insufficiency of medical data, the expenses for the supervised training of a report generation framework is relatively high. Liu et al.214 proposed the knowledge graph auto-encoder (KGAE), an unsupervised encoder-to-decoder method to achieve the automatic generation of medical report without the strict restriction on the paired training data set. Specifically, KGAE214 set the knowledge graph to come across the gap between visual and textual modality. The encoder and decoder of KGAE,214 with a knowledge-driven aid, associated the images with the report context in the shared latent space. In Figure 8, the framework and outcome of KGAE was shown. At present, the recurrent attempts to generate the medical report suffered from the top-down features, which consumed much time and showed an inefficiency in comprehending the report. Therefore, Xiang et al.211 proposed an encoder-to-decoder framework, in which the encoder part grasped the visual features while the decoder part performed the computation in parallel to improve the computational efficiency. This design, names RTMIC,211 got trained via a reinforcement learning and received a performance that was superior to other state-of-the-art results.

7.3 X-ray report
The Transformer-based attempts to attempted to explore the automated generation of accurate and fluent X-ray reports included.217-222 As for the X-ray medical report generation, You et al.219 build an AlignTransformer to reach the correspondence between the visual regions with the disease tags. The authors divide the task into two parts: the first part is the prediction of disease tags and the feature extraction of the relation between the images and the disease tags while the second part is to produce the medical report based on the extracted information. In practical, the authors launch an align hierarchical attention (AHA) module for the former task and the multigrained transformer (MGT) for the latter. Tested on public datasets, extensive experiments demonstrate that the AlignTransformer outperforms other competing methods and receives the evaluation support from the professional radiologists.
8 MEDICAL IMAGE REGISTRATION
Information in a single medical image, no matter how rich it is, is limited to one angle due to the inferior 2-dimension restriction of the image modality. However, for different medical images on a shared target under different realistic conditions, the employment of Artificial Intelligence can help fuse the information from the different incomes with an enlargement of richness and dimension of the original image information. Vision Transformer, as one of the most advanced models in CV, have shown to perform well in terms of image registration and the corresponding papers is summarized in Table 6.
| Name | Modality | Organ/Method | Disease/Dimension |
|---|---|---|---|
| FPT223 | US | Bone | Spine |
| XMorpher224 | Multimodality | Pure Transformer | None |
| Yibo Wang225 | Multimodality | UNet-based | None |
| C2FViT226 | Multimodality | CNN-based | None |
| ViT-V-Net227 | Multimodality | UNet-based | None |
| TransMorph228 | Multimodality | CNN-based | None |
| LKU-Net229 | Multimodality | UNet-based | None |
| TD-Net230 | Multimodality | CNN-based | None |
| GraformerDIR231 | Multimodality | CNN-based | None |
| CEMSA232 | Multimodality | UNet-based | None |
| ADMIR233 | MRI | Brain | Drug addiction |
| PC-SwinMorph234 | MRI | Brain | None |
8.1 MRI
8.1.1 Fetal brain registration
Xu et al.176 propose to introduce the Transformer to the slice-to-volume registration task. The authors take multiple MRI slices as a sequence and exploit the attention mechanism's potential on the automatic detection on the inter-slice relevance and the unknown slice prediction. In Xu et al.,176 the authors also give estimations on 3D volume, which are updated to the model to promote the accuracy. Experimental results show that this framework reaches the reduction in registration error and the improvement in reconstruction quality. To have a knowledge of to what extent this proposed model can boost the 3D reconstruction quality, the authors conduct extent experiments on real-world MRI data.
8.1.2 Drug addiction brain registration
Tang et al.233 propose an ADMIR (Affine and Deformable Medical Image Registration) as an unsupervised solution to the medical image registration. This work in Tang et al.233 consists of three modules: the registration module computes the parameters of affine transformation; the deformable registration module builds the displacement vector field; the spatial transformer module absorbs the output of the former two modules and generate the final image. The performance of ADMIR gets evaluated on some MRI data collected on drug-addicted brains and appears to outperform other competing methods in terms of important indicators in medical registration task. Notably, ADMIR can be applied to medical registration task with high accuracy and speed.
8.1.3 Brain registration
Liu et al.234 intend to achieve both the registration and the segmentation of medical images through a novel framework named SwinMorpy. In an unsupervised manner, this model explores the patch representation to boost the ultimate performance. In concrete, the authors introduce a patch-based strategy to capture rich local features and the other patch stitching strategy based on a multiattention backbone with a 3D shifted window mechanism. The experimental results, provided in Liu et al.,234 have shown this model's superiority over other state-of-the-art works.
8.2 Multimodality
8.2.1 Pure Transformer-based
Shi et al.224 present a XMorpher to fulfill the medical image registration task based on pure Transformer backbone. The attention mechanism in Transformer was modified into a cross attention transformer (CAT) in this paper to ensure a sufficient interaction between moving images. On the foundation of the CAT block, the authors in Shi et al.224 design a dual network to capture the features of input images. Then, the multilevel features get incorporated, by means of the fusion module, into the comprehensive representation of the feature. With the help of CAT block, this network can exploit the potential of attention mechanism in terms of the alignment of different images. As a result, XMorpher achieved a computational progress in efficiency and the smoothing of interference.
8.2.2 U-Net-based
Some researchers placed emphasis on how to integrate the Transformer with the U-Net to boost the performance of registration, including.225, 227, 229, 232 Wang et al.225 proposed to join the Transformer with the U-Net structure for the medical image registration. Specifically, the authors utilize the distinctive Transformer structure to capture global and local features, both of which are used for the supervised generation of registered images. The design in Wang et al.225 can boost the registration accuracy, which has been validated by the experimental results on brain MRI datasets. According to the extensive experiments on LPBA40 and OASIS-1, the work in Wang et al.225 outperforms other registration frameworks, whether conventional or DL-based, in terms of registration accuracy.
8.2.3 CNN-based
In Refs,226, 228, 230, 231 authors constructed the framework with a combination of CNN and Transformer. In medical image registration, affine registration plays an indispensable role. Previous attempts on affine registration target at how to boost the speed of affine registration, most of which based the framework on CNN. In Mok and Chung,226 the authors propose a novel Coarse-to-Fine ViT, which exploited both the globality and locality of model. This work in Mok and Chung226 introduced the convolutional operation into vision Transformer. Experimental results on 3D brain datasets show that Coarse-to-Fine ViT outperforms other CNN-based works.
9 MEDICAL IMAGE SYNTHESIS
9.1 MRI
MRI is one of the noninvasive medical modalities that carry much crucial detailed information, especially for the structural development of human brain. Across different stages of life, MRI can be employed for the comprehensive analysis of neurodevelopment. Although the MRI analysis is of great abundance for adults, the researchers are highly short of MRI images on infants. Infants are customed to be opposed to staying still and keeping concentrated, which is quite influencing to the collection of MRI images. The authors in Zhang et al.235 notice the data shortage of infant MRI images and correspondingly propose a novel pyramid transformer net (PTNet) to achieve the synthesis of MRI. Specifically, PTNet combines the Transformer layer with multiscale pyramid design. Experimental results showed that PTNet outperformed other GAN-based models.
9.2 PET
It is challenging to practice the medical image synthesis task on PET images owing to their intensity range and density degree.
As for the PET images, the intensity values are of great significance during the computation of reproducible parameters but intensity range is so fluctuating that the manual intervention is commonly required. Therefore, the authors in Shin et al.236 propose GANBERT with a comprehensive integration of BERT with GAN. In the process of PET synthesis, BERT takes the responsibility for predicting some masked value images while the GAN discriminator is based on the “next sentence prediction (NSP)” part of the BERT. As the result, the manual effort in adjusting the PET synthesis gets replaced by the GANBERT. The further evolvement of GANBERT may be led to the introduction of U-Net architecture as the generator or the NSP as the GAN discriminator.
9.3 CT
The authors in Ristea et al.237 propose an image translation method for CT scans. The transform from unpaired contrast CT scans into noncontrast CT scans may both supplement the contrast CT scans source and the pairing of contrast and noncontrast CT scans.
Therefore, in Ristea et al.,237 the authors propose the CyTran, which bases its foundation on GAN and Transformer. Fed with unpaired CT images, this neural network employed a cycle-consistency loss to promote the training effect. For the sake of the property of high-resolution CT scans, CyTran joins both the convolutional and Multi-Head Attention mechanism for the registration of CT scans. Coltea-Lung-CT-100W, as a novel data set with 37,290 lung CT images, was specifically built for the training of CyTran. Experimental results showed CyTran's superiority over other competing methods in medical image synthesis.
9.4 OCT
Dye injection, as an effective method for tracking the vascular structure of retina, may lead to serious side effect on health while the color fundus imaging fails to meet the fidelity requirement despite its noninvasive property. As the mere noninvasive option for retinal vasculature capturing, optical coherence tomography-angiography (OCTA) can only guarantee the stable imaging of rather small areas on the retina, not to mention its relatively high expense. In Kamran et al.,238 the authors introduced deep learning framework, specifically GAN, for the synthesis of Fluorescein Angiography (FA) images based on the fundus photo input. This network, as is called VTGAN in Kamran et al.238 merits both a noninvasive solution to retinal vasculature imaging and an effective prediction tool to detect the retinal abnormalities. Experimental results of VTGAN showed its superiority over the state-of-the-art frameworks in terms of fundus-to-angiography synthesis.
9.5 Multimodality
The collection of complementary tissue morphology information can promote the clinical practice of disease diagnosis. On the other hand, the scan cost makes it difficult to widen the application of tissue morphology information acquirement. To balance the effect with the expenses, medical image synthesis can be applied to this problem. Among the recent methods for medical image synthesis outstand the GAN-based models owing to their excellent ability to comprehensively concentrate on the structural details. However, GAN, with a main framework based on CNN, also inherited a locality bias and spatial invariance, which rises as an obstacle before the development of long-range dependencies. Therefore, Hu et al.239 proposed a cross-modal framework for the medical image synthesis with a double-scale deep learning method. Concretely, this work239 based the local discriminator on CNN and the global discriminator on Transformer and joined them into a double-scale discriminator. Evaluation on standard benchmark IXI data set showed promising results in Table 7.
10 MEDICAL IMAGE DATASETS
One of the major limitations regarding medical datasets is that not enough data is available to train a Transformer model, especially compared with that in CV and natural langue prepossessing community. Recently, this phenomenon has drawn increasingly attention. Researchers have made tremendous efforts to construct high-quality datasets. We summarize popular datasets used in various medical image analysis tasks in Table 8. As can be seen, classification and segmentation are two most concerned tasks. Datasets designed for other tasks such as synthesis, detection and reconstruction are relatively in the minority. However, in practice, we recommend researchers make full use of existing datasets for different tasks with the help of the advanced techniques in deep learning community such as weakly supervised learning, multimodal learning, multitask learning, transfer learning and selfsupervised learning. For example, backbone models could be learned on datasets designed for segmentation using selfsupervised learning with carefully designed pretext tasks. This backbone is then used as the input for downstream tasks such as synthesis and detection tasks. In this way, all datasets in the community are fully leveraged for various tasks.
| Name | Modality | Organ/Method | Disease/Property | Task |
|---|---|---|---|---|
| PPMI242 | Multimodal | Brain | Parkinson | Synthesis |
| BRATS243 | MRI | Brain | Brain | Synthesis |
| iSeg-2017244 | MRI | Brain | Brain tissue | Segmentation |
| BraTS-2020245 | MRI | Brain | Brain tissue | Segmentation |
| MRBrainS246 | MRI | Brain | Brain tissue | Segmentation |
| UKBB247 | MRI | Brain | Brain tissue | Segmentation |
| ERI248 | MRI | Cardiac | Cardiac | Segmentation |
| CHAOS249 | MRI | Abnominal | Abnominal | Segmentation |
| KiTS19250 | CT | Pediatric | Pediatric | Segmentation |
| USCD251 | CT | Eye | Drusen | Segmentation |
| MSD-01252 | CT | Multiorgan | Multi | Segmentation |
| M& Ms253 | MRI | Cardiac | Cardiac | Segmentation |
| ISIC2017254 | Dermo | Skin | Melanoma | Segmentation |
| GlaS255 | Histopath | Colorectal | Cancer | Segmentation |
| MoNuSeg256 | Micro | Cell | Nuclear | Segmentation |
| Pannuke257 | Micro | Cell | Cell | Segmentation |
| NIH Chest258 | X-ray | Lung | Lung | Segmentation |
| Clean-CC-CCII259 | CT | Lung | COVID-19 | Segmentation |
| Bowl260 | Micro | Cell | Nuclear | Segmentation |
| Thorax-85261 | CT | Multiorgan | Multi | Segmentation |
| SegTHOR262 | CT | Thoracic | Thoracic | Segmentation |
| ACDC263 | MRI | Multiorgan | Multi | Segmentation |
| Kvasir-SEG264 | Colon | Gastrointestinal | Polyp | Segmentation |
| Clinic DB265 | Colon | Gastrointestinal | Polyp | Segmentation |
| EndoScene266 | Colon | Colorectal | Polyp | Segmentation |
| ETIS267 | Colon | Colorectal | Cancer | Segmentation |
| Choledoch268 | Histopath | Cholangio | Cholangiocarcinoma | Segmentation |
| TCIA269 | Multimodal | Multiorgan | Cancer | Segmentation |
| HECKTOR270 | PETCT | Headneck | Tumor | Segmentation |
| REFUGE20271 | Fundus | Eye | Glaucoma | Segmentation |
| CVC272 | Colon | Colorectal | Polyp | Segmentation |
| Alizarine273 | Fundus | Eye | Corneal | Segmentation |
| EchoNet-Dynamic274 | Echocardiography | Cardiac | Ventricle | Segmentation |
| CBIS-DDSM275 | CT | Breast | Mammography | Segmentation |
| DIARETDB1276 | Fundus | Eye | Retinal | Segmentation |
| STARE1 | Fundus | Eye | Retinal | Segmentation |
| IU Chest X-ray277 | X-ray | Chest | Drusen | Report generation |
| MIMIC-CXR278 | X-ray | Eye | Drusen | Report generation |
| PadChest279 | X-ray | Chest | Lung | Report generation |
| Ffa-ir280 | Multimodal | Multiorgan | Multi | Report generation |
| DeepOpht281 | Fundus | Eye | Retinal | Report generation |
| IH-AAPM Mayo282 | PETCT | Abnominal | Abnominal | Reconstruction |
| Kirby21283 | PETCT | Multi | Multi | Reconstruction |
| DIV2K284 | MRI | Multi | Multi | Reconstruction |
| fastMRI285 | MRI | Multi | Multi | Reconstruction |
| dHCP286 | MRI | Brain | Infant | Reconstruction |
| NIH-AAPM287 | LDCT | Liver | Liverlesion | Reconstruction |
| Open MPI288 | MPI | Multiorgan | Multi | Reconstruction |
| COVIDGR-E289 | X-ray | Lung | COVID-19 | Detection |
| IDRiD290 | Fundus | Artery | Microaneurysm | Detection |
| COVIDx-CT-2A291 | CT | Lung | COVID-19 | Detection |
| Cancer Genome Atlas292 | Histopath | Cancer | Multitype | Detection |
| LUNA293 | CT | Lung | Nodule | Classification |
| LIDC-IDRI294 | CT | Lung | Nodule | Classification |
| Saber295 | CT | Lung | Emphysema | Classification |
| COVID-CT296 | CT | Lung | COVID-19 | Classification |
| Sars-CoV-2297 | CT | Lung | COVID-19 | Classification |
| COVID19-CT-DB298 | CT | Lung | COVID-19 | Classification |
| COVID-CTset299 | CT | Lung | COVID-19 | Classification |
| BIMCV COVID19300 | X-ray | Lung | COVID-19 | Classification |
| PosteriorAnterio301 | X-ray | Lung | COVID-19 | Classification |
| COVIDx302 | X-ray | Lung | COVID-19 | Classification |
| Color Fundus303 | X-ray | Eye | Retinal | Classification |
| Cohen304 | X-ray | Lung | COVID-19 | Classification |
| CHOWDHURY305 | X-ray | Lung | COVID-19 | Classification |
| Cohen's data set306 | X-ray | Lung | COVID-19 | Classification |
| Kather307 | X-ray | Colorectal | Cancer | Classification |
| BUSI308 | US | Breast | Cancer | Classification |
| Data set B309 | US | Breast | Cancer | Classification |
| CAMELYON16310 | Micro | Lymph | Node | Classification |
| TCGA-NSCLC311 | CT | Lung | Cancer | Classification |
| RFMiD2020312 | Fundus | Eye | Retinal | Classification |
| Messidor313 | Fundus | Eye | Retinal | Classification |
| EyePACS314 | Fundus | Eye | Retinal | Classification |
| CheXpert315 | X-ray | Lung | COVID-19 | Classification |
| POCUS316 | X-ray | Lung | COVID-19 | Classification |
| Qi317 | X-ray | Lung | COVID-19 | Classification |
11 DISCUSSIONS AND CONCLUSIONS
This paper reviews the literature of Transformer-based models for medical image analysis. We consider most of popular tasks such as classification, detection, segmentation, reconstruction, registration, synthesis, and clinical report generations. On the other hand, in each task, we review existing works for different types of input resource, for example, X-rays, CT Scans, MRIs, fundus and multimodals. We also summarize the popular datasets for medical image analysis according to input modalities, organs, methods, diseases, properties and tasks. These efforts hopefully assist researchers move forward in the field of medical image analysis, especially with the help of Transformers. To keep pace with rapid development of Transformers in deep learning community, we recommend organizing the relevant workshops in CV and medical imaging conferences and arranging special issues in prestigious journals to promote research in medical image analysis.
Transformer, as one of the most powerful models currently in NLP and CV, has been applied to many areas. The long-range dependency of Transformer makes it capable of grasping the deep features hidden in an image. However, despite the previous success of Transformer in other areas, it remains challenging for the integration of Transformer and medical images. On the one hand, apart from the excellent performance, Transformer also consumes much computation and requires a large data set for training. On the other hand, the specificity of medical images, such as the unabundant amount and the strict realistic constraints, also sets some challenges for the researchers who attempted to introduce the Transformer for medical tasks. These conflicts, along with the other detailed obstacles in the clinical practice stood against the launching of Transformer based on medical images.
Thankfully, with the continuous efforts and the spectacular talents of researchers, as our review has shown, many innovative Transformer-based methods have been proposed for medical tasks. From specific disease to general examine, many researchers have given their solution to facilitate the computer-aided medical image analysis. As the result of their works, the advantage of Transformer is maintained on medical tasks. Ranging from segmentation to registration, Transformer has been efficient in reaching the target in medical image-based tasks.
We firmly believed that as science develops, the integration of different subjects may play an increasingly important role in the future. And these Vision Transformer-based trials in medical imaging area is another proof that one of the most advanced AI models can joined with the exploration of some frontier clinical problems. With the rapid growth of research using Transformers in the field of medical image analysis, we hope this review provides a road map to researchers to move forward in this field conveniently.
AUTHOR CONTRIBUTIONS
Kun Xia: Conceptualization (equal); investigation (equal); resources (equal); writing—original draft (equal); writing—review and editing (equal). Jinzhuo Wang: Conceptualization (equal); funding acquisition (lead); investigation (equal); resources (equal); writing—original draft (equal); writing—review and editing (equal). Both authors have read and approved the final manuscript.
ACKNOWLEDGMENTS
This research was supported by Discipline Development of Peking University (7101302940,7101303005) and the National Natural Science Foundation of China (62172273).
CONFLICT OF INTEREST STATEMENT
The authors declare no conflict of interest.
ETHICS STATEMENT
This work needs no ethics approval.
Open Research
DATA AVAILABILITY STATEMENT
This work does not contain data and code.

