

Smart contract formation enabling energy-as-a-service in a virtual power plant
Funding information: Eesti Teadusagentuur, Grant/Award Number: PUTJD915; Ministerio de Economia y Competitividad, Grant/Award Number: TIN2017-84553-C2-2-R; Ministerio de Ciencia e Innovación, Grant/Award Number: PID2020-113614RB-C22
Summary
Energy as a service (EaaS) is an emerging business model that enables the otherwise passive energy consumers to play an active role and participate in the energy utility services. This platform is formed through smart contracts registering peer-to-peer (P2P) transactions of energy through price and quantity. Many industries, including finance, have already leveraged smart contracts to introduce digital currencies. At this time, the utility industry is faced with the challenge of how to structure smart contract formation in a local energy market. Specifically, they are faced with the challenge of maintaining a balance between energy generation and demand while enabling traceability, security, and unbiased peer-to-peer energy transactions, especially within a virtual power plant. This article aims at addressing the aforementioned challenges. In particular, this article investigates how to structure the microgrids in a local energy market, and how to ensure balance and resiliency with incomplete information. Taking various generation asset dimensions and demand profiles into account, simulations are performed. A novel evolutionary computing strategy to structure the simulation is proposed. A comparison is made among random order, random selection, profit-based ranking, and evolutionary strategy for coordinating the contract formation. The discussions draw attention to each method's advantages and disadvantages in terms of their value as a strategy for forming smart contracts in a local energy market.
1 INTRODUCTION
The current environmental challenges due to global warming, together with the increasing prevalence of renewable resources, are behind the rapid emergence of distributed energy systems. Indeed, distributed energy systems have been recognized as an efficient, resilient, and environmentally friendly alternative to the existing traditional energy system.1 Distributed energy systems consist of small-scale power generators located within the electric distribution system at or near the end users. Since they are characterized by multi-generation and have an emphasis on clean energy and low emissions, they are increasingly attracting attention.2 Distributed energy systems represent a paradigm shift, as they provide consumers with opportunities to reduce costs and can increase revenues through local generation and load management. This customer-centric paradigmatic shift is the main impetus behind the modern concept of energy as a service (EaaS) that is recently discussed in the literature.
“At its most basic, EaaS can be defined as a model that applies innovative technology and data management in ways that give customers more control over how much power they use and what they spend for it.”3 Examples of EaaS include energy management for data centers, charging infrastructure for electrical vehicles (EVs), fuel cost optimization for airlines, and energy risk management.4 EaaS often involves innovative business models that use customer information to create value. EaaS is empowered by peer-to-peer (P2P) energy trading and business models for local energy markets. Indeed, with the increasing connectivity between distributed energy resources, the new concept of a prosumers arises. A prosumer is one who both consumes and generates energy. P2P energy trading represents direct energy trading between peers, who buy or sell energy directly with each other, without the involvement of conventional energy suppliers.5 P2P energy trading is usually implemented within a local electricity distribution system; thus, it is tightly connected to the concept of local energy markets. Local energy markets are organized in a decentralized fashion, and they can significantly contribute to decreasing the need for extensive investments in transmission capacity.6 P2P energy trading and local energy markets are novel concepts that have received increasing attention in the recent literature. This is due to advancements in online services based on information and communication technologies (ICTs). ICT-based services enable, support, and enhance the concrete implementation and investigation of such novel frameworks.7 State-of-the-art analyses and perspectives for P2P energy trading are discussed in Reference 8. A review of existing P2P energy-trading projects can be found in Reference 9 whereas a review of architectures, distributed ledger technologies (DLTs), and market analysis for microgrid (MG) transactive energy (TE) can be found in Reference 10. An assessment of the P2P energy-trading potential for the residential sector is provided by Reference 11. The P2P trading concept has been addressed within a wide range of applications, such as within community MGs,12 federated power plants,13 smart homes,14 home energy management and distributed optimal power flow,15 EVs,16 and low voltage electrical distribution networks.17 Peer-to-peer energy trading requires the design of novel local energy markets. An optimization-based market clearing design, which incorporates multiple energy carriers and is intended for use with local energy markets, is proposed in Reference 18, whereas a hybrid trading network construction for local energy markets is discussed in Reference 19. Paths towards integrated, open, and distributed energy markets are also discussed in Reference 20. Local energy market strategies are discussed in Reference 21, and a novel virtual energy hub plant located within a thermal energy market is proposed in References 22 and 23. Consumers' viewpoints on new energy markets have been gathered in Reference 24, and real-world case studies have also been implemented and investigated, such as References 25-27.
Recent advancements in information and communication technology have contributed to peer-to-peer energy trading and to energy markets, especially through the novel concepts of blockchain and smart contracts. A blockchain is a distributed software system that allows transactions to be processed without the necessity of a trusted third party.28 It leads to a quicker and cheaper completion of business activities. The blockchain technology enables smart contracts, defined as computer programs or transaction protocols that “automatically, execute, control or document legally relevant events and actions according to the terms of a contract or an agreement.”29 Blockchain-based P2P energy trading is becoming very popular in the scientific literature, and many recent works such as References 30-32 have addressed this concept, where the latter is even proposing a pilot energy-trading platform. In terms of concrete implementations, virtual power plants (VPPs) represent a real-world application with challenges and opportunities. As described in Reference 33, a VPP is a system that integrates several types of power sources. The main objective of a VPP is to give a reliable and power supply. The sources of a VPP are often a cluster of distributed generation systems with intermittent renewable energies. The authors in Reference 34 introduce the novel concept of P2P energy trading in a VPP based on blockchain smart contracts. Another blockchain-based energy-trading mechanism for VPPs is proposed in Reference 35, whereas authors in Reference 13 address the use of peer-to-peer energy-trading platforms to incentivize prosumers to form federated power plants. However, while the scientific literature addresses P2P energy trading and blockchain-based smart contracts within MGs and households, there is not much work carried out within the field of VPPs.
- Proposing a novel evolutionary computing strategy.
- Comparing this novel strategy with two traditional strategies (random selection and profit-based ordering) and determining which strategies are most suitable for which scenarios.
This article addresses a scenario where multiple picogrids are participating in a VPP as asset owners and addresses the challenge of how different smart contract formation can facilitate energy transactions in this scenario. To the best of the authors' knowledge, there is no existing research available that considers energy as a service within a VPP.
1.1 Paper objective and proposed approach
As outlined in the previous section, although there is a plethora of scientific literature available on the topics of P2P energy trading and blockchain, the main applications are currently in the subjects of smart grids and behind-the-meter, yet very little work is available on the topic of VPPs. The convergence of the virtual layer (blockchain) and the physical layer (power system) forms a VPP, and this lesser studied area of convergence motivates this research. This is why the main objective of this article is to study blockchain-based smart contract formation for particular application to VPPs, as this subject has not yet received a wide attention in the literature.
The main problem addressed in the article can be summarized as follows. Smart contracts are used to facilitate peer-to-peer energy transactions. When a large number of prosumers want to make energy transactions, the challenge for the network operator is to coordinate and organize the transactions so as to ensure the security and reliability of the power supply. This article investigates a resolution to this problem by evaluating three different strategies for forming smart contracts in ways suitable to handle large numbers of energy transactions. Comparisons between the different strategies are based on profit and asset installation.
The proposed approach is highly interdisciplinary, involving subjects at the intersection of power systems and engineering, computer science, mathematics, and economics, which together can be referred to the emerging domain of Energy Informatics.36 From a power system and engineering perspective, the proposed article focuses on the concept of VPPs. From a computer science perspective, the article proposes the use of genetic and evolutionary computing approaches.37 Mathematics is brought into the picture through the use of mathematical optimization approaches. Finally, the field of economics is involved via the concepts of local energy markets and smart contracts, which are at the heart of the proposed work.
1.2 Challenges and solutions
VPPs are now increasing with both size and numbers across the world. VPPs are typically formed by pooling assets together from geographically distributed resources. This article moves the focus towards the coordination of transactions and assets within the VPP. We are interested in particular in a novel transition from a small number of big assets, towards a large number of small assets within a VPP. This interest is motivated by the increase in distributed energy resources that characterize the current energy systems. The transition requires facilitating peer-to-peer transactions among the asset owners and other stakeholders through energy-as-a-service business models. This article addresses a scenario where multiple picogrids are participating in a VPP as asset owners. The challenge the article addresses is how different smart contract formation can facilitate energy transactions between picogrids within a VPP. To the best of the authors' knowledge, there is yet to have any research works available that considers energy as a service within a VPP.
Figure 1 presents an overview of the existing challenges and the modelling techniques and paradigms that can be used to address these challenges. The lower part of the figure presents the advantages of smart contracts and how smart contracts can be a solution for addressing the challenges outlined on the left side. Each box shown on the left side of the figure is connected to boxes on the right side, in order to schematically identify the key features of the proposed model that are meant to address a specific challenge.

1.3 Key contributions
The key contribution of this article is to propose a comparative analysis of energy-as-a-service business model for a blockchain-based local energy market. A comprehensive case study is performed including 10 test cases with 10 grids in each test case. Each test case includes various capacities of generation units and load demand patterns. Four strategies—namely self-contained, random ordering, profit-based ordering, and evolutionary ordering of grids—are compared and contrasted. In total, 1200 simulations are carried out for this investigation. The evolutionary computing strategy is proposed with the fitness criteria of maximizing profit, while ensuring an efficient utilization of the total energy produced from renewable resources. The analysis clearly indicates how different smart contract formation strategies perform. The proposed evolutionary strategy is distinctly (over 40%) performing better during the winter in comparison with the other strategies. Electricity tariffs are a key parameter that would impact or influence the smart contract formation. Distribution system operators are actively investigating how to formulate the dynamic tariffs such as time of use or volume of consumption. This work also includes a series of simulations with different distribution grid tariffs to demonstrate the sensitivity of smart contract formation when the network tariff increases or decreases. It was observed that, with an increase in the tariffs, the number of contracts formed is reduced significantly, and likewise when tariffs decrease, more contracts are formed. This shows that regulating the tariffs would facilitate local energy market formation, and thereby, a policy of regulation is required. Moreover, this work can represent a basis to form or revise policies for local energy markets through smart contracts. It is more important than ever as more and more small- to medium-scale generation units are being integrated into the grid or are being deployed behind the meter to meet the demand locally.
2 EXPERIMENT FORMATION AND DATASET
The simulation includes 10 grid data files. Each file represents 10 unique, individual grids. Each grid data file initializes the demand at each node, existing sources of generation (wind or solar PV generation accompanied by a quantity of battery storage), and their associated costs occurring from investments and operations. The grid data file also consists of price information: PriceA and PriceB. PriceA is the procured price for underutilized electricity procured from a conventional source (EA), and PriceB is the procured price for underutilized electricity based on renewable resources (EB) from an adjacent grid. The time horizon considered for this study is hourly data, for 7 days, for five nodes. Each node is characterized by its own demand, generation capacity, production, and electricity storage capacity. For simulation purposes, the data profiles used are representative of both winter and summer electricity consumption and generations typically noticed in Northern Europe.38, 39 The demand, wind/solar generation, PriceA, PriceB, and tariff profiles for each of the 10 grid data files (each representing 10 individual unique grids) are plotted in Figure 2 along with their assigned colors.

Winters are characterized by high wind generation overnight and in the early morning—typically from 10 pm to 5 am—and low to medium wind generation during the daytime between 7 am and 8 pm. Twin peaks characterize demand: one peak in the morning between 6 and 9 am, with medium to high consumption during the rest of the day (due to heating, lighting, and other factors), followed by a subsequent peak in the evening between 6 and 9 pm. There is relatively low demand from 9 pm until 6 am the next day. Summers are normally characterized by very high Solar PV generation early in the day from about 5 am, lasting late in the evening until around 7 or 8 pm. Twin peaks typically characterize the demand profile during summer, one in the morning between 6 and 9 am, followed by low to medium consumption during the rest of the day, with another peak in the evening between 6 and 9 pm, followed by relatively low demand until 6 am the next day.
The input parameters from the grid data files represented in Figure 2 above are cumulative demand, wind production during winter, cumulative solar PV production during summer, procurement price of conventional energy (PriceA), and procurement price of renewable energy (PriceB) with a week-long time horizon and hourly resolution for each of the 10 grids. The price of conventional energy (PriceA) is higher than the price of renewable energy (PriceB).40 Moreover, the operational cost of battery assets throughout the vast majority of the entire analysis period is less than that of PriceA and PriceB, to facilitate better utilization of grid battery assets. A set of 10 grid data files together comprises one test set. The test table is made up of 10 test sets, each test set with the same 10 grid data files representing the individual 10 grids ordered randomly. Figure 3 displays the test table used for the simulations. The color coordination helps to identify which grid data file is in which position for each of the 10 test sets. The test table is the same for both summer and winter simulations.

- Test Set 1—a reference or base level tariffs of PriceA and PriceB
- Test Set 2—PriceA and PriceB tariffs 2 times (2×) the base level
- Test Set 3—PriceA and PriceB tariffs 1.5 times (1.5×) the base level
- Test Set 4—PriceA and PriceB tariffs 0.5 times (0.5×) the base level
- Test Set 5—PriceA and PriceB tariffs 0.25 times (0.25×) the base level
Figure 4 presents the four different PriceA and PriceB tariff levels against the base PriceA and PriceB tariffs. To isolate, visualize and discern the effects of price signals through tariffs, a set of 10 grid data files are used. These 10 grid data files are arranged in the same order, and they are used across the five test sets for simulations. The only parameters that change between the five test sets are the tariffs, that is, PriceA and PriceB. These tests are simulated for both summer and winter seasons.

3 CONSENSUS FORMATION AND SPECULATIONS
3.1 The distribution ledger technology
The DLT provides a platform for deploying decentralized applications with no central authority for storing and sharing transactions across multiple ledgers. These ledgers are where the users store data. In DLT, the flow of data is represented in the network as transactions between peers. To ensure ownership, validations, and immutability, ledgers need to use special data structures, see Reference 41. There are currently two types of data structures used in ledgers, blockchain and direct acyclic graphs (DAG), see Reference 42. Blockchain is the most popular among the two structures. It uses blocks to store data under cryptographic and algorithmic methods, recording and synchronizing the data across the network, thus ensuring the aforementioned ownership, validation, and immutability. The blockchain structure is implemented in well-known platforms such as Bitcoin, Ethereum, and Chainlink. The literature, such as References 43 and 44 or 45, shows that DLT provides hidden data, non-traceability, decentralized and transaction validation using key encryption, zero-knowledge proof, ring signatures, or holomorphic encryption. In this context, smart contracts allow for automation on a DLT to go beyond the mere execution of transactions. They enable the execution of arbitrary code in a decentralized location, which is unforgeable, meaning no single party can manipulate it (see Reference 46) Smart contracts imply computing and time resources in the distributed ledgers, so this is normally limited and measured. For example, in Ethereum,47 each operation is paid for using gas, preventing an attacker from running long tasks or infinite loops. Finally, in DLT, there are actors that provide a secure connection between the blockchain and outside services. These “oracles” are a third party and trusted authority.48
Figure 5 depicts a DLT that connects energy generation and energy consumption and illustrates the elements of networking them together.49 The generation side is typically made up of different generating assets including PV farms, (like solar or wind farms), conventional generation types, and grid electricity storage. Similarly, the consumption side constitutes different consumer types like inflexible or flexible consumers, either of whom can be residential or large industrial consumers. In this context, energy generators and consumers need to share data and smart contract with negotiated rules. The generator needs to satisfy the demand of a consumer according to an agreed upon price during a period of time, while the consumer pays for this service at a fixed price. Consumers and generators do not know anything about each other; thus, decentralized sovereign ids and oracles must ensure that both actors are valid consumers without the need for them to exchange credentials, allowing non-biased negotiations.

The DLT block shows the different DLT technologies like BlockDAG (block directed acyclic graphs) and HashGraph with a special focus on blockchain with its many variations.
3.2 Blockchain variations and consensus mechanisms
Depending on the requirements for the application being considered, different blockchain-based variations can be used. For example, blockchains with different consensus mechanisms and those with different blockchain access and update controls, as well as those with different data storage, managing, and cryptography techniques can be used. Methods to update the blockchain can be permissioned or permissionless. Simultaneously, access to the blockchain can be made public, private, or restricted to a consortium of users. Blockchain transactions can take place on-chain or off-chain, or with different consensus protocols and data managing methods. Data can be stored on a Cloud platform, on premise, in the cache, or among the peer-to-peer (P2P) nodes. The data domain block in Figure 5 incorporates the different elements used to handle blockchain data. They include the cryptographic protocols, the transaction model, the hash (which is used to identify the previous block), the digital signature (imparted when creating a block), and the data block header (which gives information about the block). Several different consensus protocols have been developed over time with varying performance levels, including scalability, throughput, latency, and other indicators as discussed in Reference 50. In Figure 5, some of these are represented in the Proof-of-X block.
Proof of Work (PoW) is very popular with cryptocurrencies like Bitcoin. PoW requires the participating nodes to spend energy solving a mathematical problem that would grant them the authority to update and add new transactions to the blockchain. Proof of Stake (PoS) designates the next block's creator through various combinations of random selection and associated collateral in the blockchain or time spent on the blockchain. Proof of Activity (PoA) is a combination of PoW and PoS, where PoW is used to mine a new block and PoS is used to reward the miner. Proof of Burn (PoB) was built as an alternative to PoW and is often referred to as a PoW system without energy waste. PoB allows the miners to “burn” the virtual currency tokens to gain authority to add a new block to the blockchain. In Proof of Value (PoV) consensus methodology each miner's (user's) authority to add a new block to the blockchain will be based on the contribution he/she delivers to the blockchain system. Proof of Importance (PoI) consensus methodology is similar to PoS. Unlike PoS, PoI considers both the resources invested in the blockchain and the user activity to maintain the blockchain. Proof of Capacity (PoC) methodology employs the node's free hard drive space to decide the mining rights and validate transactions. In PoA consensus methodology, a small number of limited nodes are handed the right to mine blocks and validate transactions onto the blockchain. In ripple consensus, each miner employs a trusted set of nodes within the larger network to reach a consensus. To reach a consensus, ripple consensus is run every few seconds to validate the blockchain. In Stellar Consensus Protocol (SCP), nodes can continue to validate their desired outcome until a consensus is reached. If a set of nodes (quorum) can't agree on what should be added to the blockchain, the entire network will cease operations until a consensus is reached. Delegated Proof of Stake (DPoS) is based on PoS consensus, which uses a technology-based democratic process to elect a group of delegates to validate blocks on behalf of all nodes in the network. In Proof of Elapsed Time (PoET), an algorithm that generates a random elapsed time, is used to decide the blockchain's mining rights.
3.3 The blockchain-based smart contract framework
A blockchain system that is tailor-made according to the requirements of the application can be constructed with a desirable combination of these different features. In this article, different consensus-building methodologies are developed, tested, and analyzed, connecting the generation side to the consumer side. The study's ultimate objective is to translate these consensus-building methodologies into a blockchain-based smart contract to automate the process of resource coordination between MGs. This blockchain smart contract will facilitate increased inter-grid (within a grid) and intra-grid (between grids) TE trading. The Blockchain Smart Contract will establish a consensus between interacting grids and between interacting players within a grid. Note that the consensus formation mechanism introduced in this article is on the top layer while the blockchain retaining the information is at the bottom; thereby, the consensus registration takes place in blockchain, while the coordination takes place on the top layer. The machine chart shown in Figure 6 depicts the different types of consensus methodologies under consideration.

The following paragraphs describe the different consensus formation methodologies with their respective mechanisms. For each of the four different consensus methodologies, a test set consisting of 10 grids represented by the 10 unique grid data files (in random order) is used as inputs.
First, in Stand-Alone Sequential consensus methodology, the grids are solved using the deterministic variant of the CoMG51 model individually, using the information of the demand, generation asset capacity, electricity generation, related costs, etc., present in the grid data files. In the case of the Stand-Alone Sequential consensus formation scheme, the grids are solved in random order. Next, in the Linked Sequential consensus methodology, the grids are solved just as in the Stand-Alone Sequential mechanism with the consensus to solve the grids in a pre-obtained order using a deterministic variant CoMG model. However, unlike in Stand-Alone Sequential methodology, an additional feature that makes the underutilized electricity generation available to the next grid, indicated by the arrow in Figure 6, is implemented. Therefore, additional electricity resources are made available to the subsequent grid. The underutilized electricity resources can be formed with a conventional resource or/and a renewable resource from the available grid.
For Profit Order Linked consensus methodology, the results from the Linked Sequential are made available to determine the profit for each grid. In this case, the consensus is to arrange and solve the grids in decreasing order by the individual grid's profits. Therefore, the grid order may change from the predetermined order. After the grids are rearranged in the decreasing order of the individual grid's profit, the grids are solved. As in the previous case, the underutilized electricity generation is made available to the next grid, indicated by the arrow in Figure 6. Finally, the genetic algorithm (GA) Order Linked consensus methodology is implemented. Here, an evolutionary computing method based on a GA is employed to arrive at a consensus on the grids' simulation order. The grid data obtained from Linked Sequential are used as inputs to the GA. The GA orders the grids based on an evolutionary strategy. The grids are then arranged according to this order, which may differ from the pre-obtained grid order. The grids are then solved in the GA determined order, using a deterministic variant of the CoMG model with the underutilized electricity generation made available to the next grid when it solves, indicated by the arrow in Figure 6.
3.4 The main consensus methodologies
- Stand-Alone Sequential—In Stand-Alone Sequential consensus formation, the grid data order is obtained through a pre-shuffle. The pre-shuffle randomly arranges the 10 grid data files in the test set. In the Stand-Alone Sequential methodology, the consensus is to solve the grid data in the pre-shuffle order. In this case, EA and EB for all the grid data files are forced to 0 for all the nodes. This means that each grid is solved in a Stand-Alone mode without interacting with the subsequent neighboring grid. The grids have to solve by themselves, taking into account the load, the existing resources (wind/PV and battery), operational costs, and investment costs if additional investments in wind/PV and/or battery storage assets are required. Here, since EA and EB are forced to 0, PriceA and PriceB are irrelevant.
- Linked sequential—In Linked Sequential consensus formation, the grid data order is the same as in the Stand-Alone Sequential method. Like in the Stand-Alone Sequential method, here too the consensus is to solve the grid data in the pre-shuffle order. However, in this case, Gridx interacts with Gridx+1. That is, each grid is connected to the next subsequent grid. Therefore, the name Linked Sequential. Here the “linking” refers to the transfer of underutilized energy, which is generated but not used in Gridx to Gridx+1. Here, CB and ER of Gridx, which is obtained after solving Gridx, is transferred to EA and EB, respectively, in Gridx+1. This is the “link” or interaction that takes place between the two grids. This effectively means that underutilized renewable energy generation (represented by ER), and battery state of charge (SoC) (represented by CB), is forwarded to the next grid for utilization if required or if economically profitable. This means underutilized wind/PV energy (ER) and unused electricity energy stored in battery storage (CB) is made available to the “next grid” in the sequence. The price associated with the purchase of the forwarded EA and EB from Gridx to Gridx+1 is represented by PriceA and PriceB of Gridx+1 for each node. It is important to remember that for Grid1, EA and EB are by default kept random since they are not connected to any previous grid.
- Profit order linked—In profit order consensus method, the consensus is to order the grid data files according to the descending order of each individual grid's profits, and the input for these profits is obtained from the results of Linked Sequential. As a result, the order of the grids, which is based on the profit order, may differ from the order of the grids in Linked Sequential. Subsequently, the grids are solved in the new profit order where Gridx interacts with Gridx+1. CB and ER of Gridx, which is obtained after solving Gridx, is linked to EA and EB, respectively, in Gridx+1, with the purchase price represented by PriceA and PriceB in Gridx+1.
- GA order linked—In this method, the consensus is obtained by passing the information in the grid data files (obtained from the results of the Linked Sequential method) into a GA. The GA reads the EA, EB, PriceA, and PriceB of each of the 10 grid data files as inputs. The GA processes this information and, using evolutionary strategies, suggests the reordering of grid data files. The grid data are then arranged in the GA's suggested order. Once the grid data files are arranged in that order, the grids are solved sequentially, where Gridx interacts with Gridx+1. CB and ER of Gridx, which is obtained after solving Gridx, is linked to EA and EB, respectively in Gridx+1, with the purchase price represented by PriceA and PriceB in Gridx+1.

3.5 Evolutionary computing-genetic algorithm
- In the context of this article, GA is employed to order the grids according to desirable features defined by the user.
- Desirable features in the grid data include nonzero values of EA and EB and low values of PriceA and PriceB.
- Here, EA and EB indicate the underutilized or unused conventional and renewable energy, respectively, generated from the previous grid.
- EA is populated with the information extracted from the SoC of the batteries installed in the previous grid, whereas EB is the underutilized renewable energy generated from wind or solar PV farms.
- PriceA and PriceB translate to the prices associated with the purchase of EA and EB, respectively.
EA, EB, PriceA, and PriceB from each of the grid data files are used as inputs in the genetic algorithm for analysis. It is important to remember that the 10 grid data files represent the 10 individual unique grids. GAs iteratively updates the population of input elements. Upon each iteration, the elements are evaluated using a fitness function. See the code representing the fitness function in Algorithm 1.
Algorithm 1. 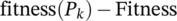 function to obtain GA scores for each generation
function to obtain GA scores for each generation
Result: Individual score for each member of 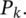
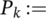 The population at generation k;
The population at generation k;
foreach 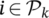 do
do
Train dataset using a logistic regression (60% of real data);
Predict using the trained model;
Append scores;
end
Sort scores;
A new generation of the population is obtained by probabilistically selecting fitter individuals from the current generation. Some of these individuals are admitted to the next generation unchanged. Others are subjected to genetic operators such as crossover and mutation to create new offspring. When the GA analysis is complete, the GA assigns each grid data file a fitness score array consisting of a series of 0's and 1's. So the grid data associated with the most number of 1's in the fitness score array are the “fittest” grid according to the GA and the grid data with the least number of 1's are the “least fit” grid. In the context of the article and analysis, “fitness” is defined as the ability of a grid to compete with other grids, with nonzero values of EA and EB and low values of PriceA and PriceB as desirable features.
Algorithm 2 represents the steps and processes associated with the proposed GA. Here, 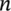 is the number of elements in the population;
is the number of elements in the population; 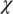 is the fraction of the population to be replaced by crossover in each iteration, and
is the fraction of the population to be replaced by crossover in each iteration, and 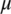 is the mutation rate. Figures 8 and 9 show the GA fitness scores of each grid for each of the 10 test sets for the two seasons. The x-axis represents the 10 different grids for each of the 10 test sets, and the y-axis represents the fitness scores.
is the mutation rate. Figures 8 and 9 show the GA fitness scores of each grid for each of the 10 test sets for the two seasons. The x-axis represents the 10 different grids for each of the 10 test sets, and the y-axis represents the fitness scores.


Algorithm 2.  Order Linked
Order Linked
Result: The grids ids ordered following the fitness score obtained.
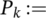 The population at generation k;
The population at generation k;
 Number of columns of data input;
Number of columns of data input;
 Maximum number of generations to evaluate;
Maximum number of generations to evaluate;
//initialization first generation;
k = 0;
foreach 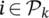 do
do
Set to 1 n_feat chromosomes;
Shuffle the array to mix 0 and 1;
Append to population 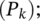
end
do
//Create next generation;
//1. Selection;
Select 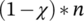 members of
members of 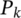 and insert into
and insert into 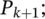
//2. Crossover;
Select 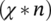 members of
members of 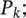 Pair these members;
Pair these members;
Produce offspring from each member;
Insert into 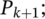
//3. Mutate;
Select 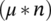 members of
members of 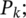
Invert randomly-selected bit in each;
Insert into 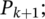
//4. Evaluate;
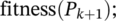
k = k + 1;
while 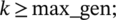
For GA-based consensus methodology, the grids (grid data files) are arranged according to decreasing order of fitness scores and the grids are solved using the deterministic CoMG model. The objective of this article is to test different consensus-forming methodologies, analyze their performances against certain basic measurable metrics, and propose them for blockchain-based P2P TE trading in MGs. We test different methodologies that use different principles for arriving at a consensus via different participants (here, the participants are the 10 grids), and we analyze the subsequent results of these tests. The results of different consensus-forming methodologies are analyzed to understand which of these methodologies performs better, under what conditions, for which type of demand, in which season, for which parameter, with what composition of the grid resources, etc. It is also important to understand which consensus-forming methodologies works “better” for which kind of renewable resource present in the grid. A wind generation profile is very different from that of solar PV production. Similarly, the same can be said about the demand profile during summer vs winter.
For analysis purposes, grid profit and underutilized energy are considered as the two analyzing metrics. More metrics can and should be considered for analysis. Here, the word “better” is subjective, with a definition that can be constructed and analyzed by the user accordingly. Performance analysis of different consensus-forming methodologies can have a profound impact in the real world in terms of economic and environmental benefits to the relevant parties. For example, this analysis gives greater insight into which consensus-forming mechanism can be used to maximize grid profits, or to reduce/avoid investments, or to maximize underutilized energy generated from the grid (while remaining in profit), or to reduce the amount of underutilized energy generated by showing better utilization of resources within the grid, etc. Thus, different consensus-forming methodologies can be deployed, switched, or alternated, depending on the objective at hand. For result analysis, two metrics have been used, profit (or investments) and underutilized energy. Profit is calculated as the total revenue minus the sum of operational costs and investment costs. If the result is positive, it indicates the grid in consideration is generating profit while if the result is negative, the grid is running costs higher than the revenue it generates.
Analysis of the underutilized energy metric when compared to the profit metric is much more nuanced and not as simple and straightforward. The underutilized energy metric is constructed as the sum total of the total SoC of the battery (wherever applicable) and the underutilized energy generated by the wind or PV farm at every node. The underutilized energy is defined as the energy generated or stored but not used by the grid in question. These two metrics are used to understand the performance of the grid with the existing resources and parameters. Ideally, it is desirable to maximize grid profit by increasing the total revenue and by minimizing the operation and investment costs. Maximizing grid profits is a favorable result taking a purely economic perspective. Underutilized energy metric is the sum of the SoC of the battery and underutilized generation of the generating assets, which refers to the energy generated or stored but not used by the grid. This perspective would indicate that it is desirable to minimize this component, that is, minimize what can be perceived as “wasted” energy. On the other hand, this underutilized energy of Gridx is transferred to the next grid in the sequence Gridx+1 so it can be used as an additional resource to solve that grid. This would mean that the Gridx+1 can avoid certain investment costs in added new generation assets and tap into the underutilized energy transferred from Gridx, thus making the overall system more profitable. This perspective would indicate that it is desirable to maximize the underutilized energy metric.
4 SMART CONTRACT DESIGN
Smart contracts allow a system to be autonomous, independent, and reliable for handling exchanges between the different actors involved. The proposed design of a smart contract is based on the consensus decisions about ordering the actors as commented on previously. In this context, energy transactions use P2P decentralized technology to ensure that consumers and suppliers exchange energy directly, based on the consensus rules (see Reference 53). The consensus rules optimize the flow between the actor (considering the current state of the system generation), demand, and prices. The actors need to sign a contract using a decentralized app where they will accept the rules and participate in the exchange. These rules are created from the optimal solution, describing the flow, amount, and price between a consumer and a supplier. Thus, each time a new actor appears in the system, the contracts must be recalculated and signed again using the app. Therefore, the smart contract must guarantee the right to participate in the system as a consumer, supplier or both, and include an operation for updating and assigning transactions between peers and for accepting the terms and conditions specified in the contract.
Algorithm 3. Smart contract: pseudocode
address owner;
Solve the consensus using ordering algorithm;
struct {
address consumer;
address supplier;
int price;
int quantity;
uint256 timestamp;
} Rule;
mapping (int  Rule) rules;
Rule) rules;
//Inject flow-rules in the contract as contract creator;
foreach 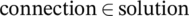 do
do
add(Rule);
end
//Give right to participate and accept conditions;
foreach 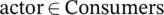 or
or  do
do
//Contract owner performs add operation using owners address;
add(actor);
//Actor performs accept operation using its own address;
accept();
end
//Actors can always check its agreements and conditions;
check();
//Transactions exchange(Rule r);
getRulesByIndex(int i);
Moreover, to insure real peer transactions, the system needs trusted, decentralized oracles that ensure and validate that a sovereign id corresponds to the user that is signing the contract and validates that signature. This way, nobody in the system needs to know private information about producers or suppliers. The system only stores information about traceability and flow of the energy, like capacity of generation, type of generation, market prices, or demand. Algorithm 3 presents a proposal for a smart contract to handle this situation. The address represents an actor's public key, which is a unique hash that identifies everyone in the system. The contract contains a collection of rules (struct Rule) that model the transaction where each supplier and consumer know the quantity and the price and the date of the agreement they must satisfy. To decide its consensus of rules, this article proposes different algorithms to order and decide the optimal connections and energy exchanges. Using the optimal solution, the contract owner inserts all the actors' suppliers and consumers into the smart contract by adding their addresses. Then, each actor must use the operation to accept and verify that they know the conditions and agree with the terms. Finally, the contract should supply other operations as well, such as to check conditions, to get rules, to make new transactions, and to get historical data. Therefore, the data stored in the smart contract will be things such as the current timestamp, market window, addresses of actors, historical records of generation/demand, and real-time transactions.
5 RESULTS AND DISCUSSION
5.1 Seasonal analysis
From the results for both summer 12 and winter 13 seasons, a pattern clearly emerges for every test set that shows the Stand-Alone Sequential consensus methodology always underperforms compared to the other “Linked” consensus methodologies in terms of the cumulative total profits. The results show that Stand-Alone Sequential, on average, makes 0.43% and 0.67% less profit than the other “Linked” methods in summer and winter seasons, respectively. Furthermore, the results clearly show that all corresponding individual grids make more profit from the “Linked” consensus methodologies, irrespective of their positions in the changed order (Profit or GA methods) or the unchanged order (Linked Sequential) methodologies, compared to the Stand-Alone Sequential methodology for both summer (12) and winter seasons (13) respectively. This is a consistent pattern.
From the previous observations, it can be concluded that the “Linking” methodologies, which make underutilized electricity generation available to the adjacent grid, reduce the grid's need to invest in additional generating assets. This is because underutilized electricity, which is shared between grids, is cheaper than investing in expensive additional generating assets for both summer and winter seasons. This conclusion is validated by the results obtained from the simulations. Figures 10 and 11 show the graphical representation of the number of additional assets installed for each of the test sets (each test set of 10 grids) and employ the four different methodologies for summer and winter seasons.


In Stand-Alone Sequential methodology, EA and EB are forced to zero. This means that EA and EB, which represent the underutilized conventional (CB) and renewable electricity (ER) from an adjacent grid, are zero. Or, in other words, the grids do not have access to this underutilized electricity generated from the neighboring grid. Therefore, to satisfy the demand, they have to invest in additional generation resources. In the “Linked” methodologies, EA and EB are populated with values of CB and ER, indicating the availability of underutilized electricity from a neighboring grid. This key difference between the two methodologies explains the patterns observed in Figures 10 and 11. It is also noteworthy that the number of additional generating assets required during the summer season for Stand-Alone Sequential is almost double that needed for the “Linked” methodologies for each test set, but that number still does not exceed 10. Notably for the winter season, the number of additional generating assets required for Stand-Alone Sequential is almost 50 units more than that of the “Linked” methodologies.
The large difference in the additional assets required to satisfy demand in winter vs summer can be attributed to the fact that in winter, the demand is higher and cumulatively more than in summer. Moreover, a different generating asset with a different generating profile and different peak generation periods is considered for the analysis, that is, solar PV generation for the summer season and wind generation in the winter season. From the scaled grid profit results in Figures 10 and 11. the plot patterns suggest that the “Linked” consensus methodologies profits in winter are more or less consistently higher than the Stand-Alone Sequential consensus methodology. The same cannot be said for the summer season (Figure 12). The plot pattern of “Linked” consensus methodologies is more varied and not consistently above the profits of Stand-Alone Sequential consensus methodology.

Interestingly, even though the individual grid profits in summer seem more varied than the scaled profits in Figure 12 for the different “Linked” methodologies, they perform comparably, with very little to differentiate between them in terms of overall system profits. When conducting a simple overall system profit comparison for summer, it is observed that GA works better in 2 of 10 test sets, whereas Profit Order Linked performs better in just one test set and for the other test sets, Linked Sequential performed better. Interestingly, unlike in summer, the individual grid profits for the winter in Figure 13 show that the different linked methodologies perform similarly to each other. Also, there is more to differentiate in the overall system profits for the different “Linked” methodologies when compared to that from the summer results. In winter, (Figure 13) Linked sequential methodology generated more profit in five test sets, whereas GA order methodology generated more profit in four test sets, and profit order generated more profit in the remaining one test set.

During summer (Figure 12) a consistent pattern is observed that all of the “Linked” methodologies produce more underutilized electricity than Stand-Alone Sequential. This can be attributed to the fact that since solar production during summer is high and grid demand is low, there is underutilized renewable electricity. This underutilized renewable electricity is being made available for utilization by the subsequent grids, and battery storage is being recharged consistently. Since the SoC of the battery is one of the two components that constitute the underutilized electricity metric, this explains this observation. It is noticed that during summer, Profit Order Linked produces on average slightly more underutilized electricity (2%) than the other two “Linked” methodologies. This may be explained by the fact that in Profit Order methodology, the grids are arranged in decreasing order of grid profit. This means that the first grid will be the most self-sufficient grid in terms of generating assets (including consideration of battery storage), whereas the last grid will be the least self-sufficient. And since demand during summer is largely satisfied by the assets already available, this means that the CB and ER (the underutilized electricity) is largely maximized for each grid, proceeding in decreasing profit order.
Winter is more difficult to analyze. There is no clear, discernable pattern for underutilized energy metrics in winter. For some test sets, “Linked” methods generate more underutilized electricity, whereas for other test sets, “Linked” methods generate less than the Stand-Alone Sequential method. It is observed that the different “Linked” methodologies produce on average almost identical underutilized energy, with nothing to distinguish between them across all 10 test sets. It is also observed from the scaled grid profit plots that Linked Sequential always outperforms in individual grid profit and in overall system profit terms when compared to Stand-Alone Sequential methodology, which is an important result considering in both of these methods the grid order is the same. This shows that having underutilized electricity generation available to the grid allows the grid to avoid expensive investments and to increase profits. This is true for both summer and winter. In fact, in winter the profit difference between Linked Sequential and Stand-Alone Sequential is greater than during summer. This may be because in winter the Linked Sequential methodology makes more substantial savings on asset investments due to increased procurement of cheap EA and EB to meet the high demand.
During summer, in profit order simulation, the grid data files are in the same order for all the test sets. This can be explained by the fact that during summer, the demand is low and solar generation is abundant; thus, there is very little, if any, utilization of EA and EB. Therefore, the profit margins are marginally influenced. During winter (Figure 10), in profit order simulation the grid data files are not in the same order for all the test sets, unlike in summer. This can be accounted for by the fact that during winter, the demand is high and the renewable generation peaks do not coincide with demand peaks, meaning the grids have to rely on battery storage and utilization of EA and EB when appropriate. This disconnect between demand peak and generation peak timing influences the grid profit margins. It should be noted that only a few grids change position in the order, and it is not the case that the grid orders across the test sets are very different.
Both for summer and winter, in GA order simulation, the grid data files are in the same order for all the test sets. This is accounted for by the fact that GA order is generated using the information of EA, EB, PriceA, and PriceB from each grid data file. This information is different for each of the 10 test sets. The change in the GA grid order from test set to test set for both seasons is wildly different. In the summer results, it is noticed that for Profit Order Linked simulation, the grids produce gradually decreasing grid profits, which is what is expected. However, in winter, with Profit Order Linked simulation, the grids produce gradually decreasing profits, with instances of a subsequent grid generating more profit than its immediate predecessor. This can be accounted for by the fact that, as discussed in the previous points, due to the demand and generation profile in winter, the grids have to rely more on EA and EB to meet high grid demand. There may be situations when EA and EB might be available at a cheaper cost to the previous grid, or that EA and EB are available in abundance, such that few generating assets can be avoided, or the grid may not need to purchase EA and EB, etc., which could result in increased profits.
Different data normalization methods have also been used to extract different information, inferences, and patterns from the results. For this analysis, mean normalization and SD normalization have been conducted. For both summer and winter, the analysis does not show deviation from what can be observed using the simple raw numeric comparison of scaled grid profits. In contrast, different normalization methods shed more light on how the individual grid profits are organized around the average and SD of overall grid profits. It is observed that the GA consensus methodology performs less consistently among its peer “Linked” consensus methodologies in terms of individual grid profits in summer. The same cannot be said for winter. With regard to overall system profits, the GA consensus methodology performs consistently with its peer “Linked” methodologies in summer. In winter, GA performed better in 4 of the 10 test sets in terms of overall system profits, whereas in the remaining six test sets, its performance was almost consistent with its peer “Linked” consensus methodologies. For GA consensus, the performance of the underutilized electricity metric is consistent for the individual grids and the overall system, with the overall trend for high underutilized electricity in summer. In contrast, in winter, there is no discernible trend visible.
The following figures, that is, Figures 12 and 13 show the scaled grid profit plots (scaled from 0 to 1) and the Grid Data Orders for Stand-Alone Sequential, Linked Sequential, Profit Order Linked, and GA Order Linked methodologies for each of the 10 test sets for both the summer and winter seasons.
5.2 Price signal analysis through tariffs
As mentioned earlier in the article, five tariff levels are used and are represented by the five test sets. For each of these five test sets, four different consensus methodologies are analyzed. Test Set 1—a reference or base level tariffs of PriceA and PriceB; Test Set 2—tariffs two times (2×); Test Set 3—tariffs 1.5 times (1.5×); Test Set 4—tariffs 0.5 times (0.5×), and finally Test Set 5—tariffs 0.25 times (0.25×) the base level.
Observable from the resulting patterns of the scaled grid profit plots, both summer (Figure 14) and winter (Figure 15) “Linked” methodologies always produce more profit for the individual grids and, as a result, produce more profit for the overall system than the Stand-Alone Sequential methodology. There is another observable pattern from the scaled grid profit plots for both summer (Figure 14) and winter (Figure 15) that as the tariffs are lowered, the individual grids produce more profits, which is what is expected. Buying underutilized resource available at cheaper rates increases profits. As individual grids make more profits as the tariffs are lowered, the overall system also makes more profits. Interestingly, it is observed that proportional change in tariffs does not produce a proportional change in profits. That is, when the tariffs are doubled (Test Set 2), overall system profits decrease slightly, but when the tariffs are halved (Test Set 4), the overall system profits increase more than they decrease when the tariffs doubled. And as the tariffs further decrease to a quarter (Test Set 5), the overall system profits increase measurably. This phenomenon is true for both summer and winter, although in winter, the shift in profit margins in this analysis is more pronounced.


These patterns can be explained by the situation that emerges when tariffs are reduced to a level where the operational cost of accessing grid storage may be higher than PriceA, PriceB, or both, for large periods of the analysis. In this situation, grids that were previously using grid storage to fulfill energy requirements end up purchasing more energy from the neighboring grid, not because grid storage is exhausted, but because it is cheaper. This situation is more pronounced in winter than in summer because in winter, the demand is higher and cumulatively more expensive than in the summer. Moreover, a different generating asset with a different generating profile and different peak generation periods also contributes to this result. From the previous observations, it can be concluded that the “Linking” methodologies, which make available underutilized electricity generation to the adjacent grid, reduce the grid's need of investing in additional generating assets. This is true for both the both summer and winter. This is because underutilized electricity, which is shared between grids, is cheaper than investing in expensive additional generating assets. Figures 14 and 15 show the graphical representation of the number of additional assets installed (required) for the different PriceA and PriceB tariff levels. Figure 14 represents the summer season results, whereas Figure 15 does the same for the winter season. Like in the results for seasonal analysis, the explanation for the reduced number of generating assets installed is the same for both seasons.
A pattern emerged indicating that as tariffs are reduced, the number of additional generating assets installed is also reduced. Conversely, as tariffs are increased, the number of additional generating assets installed also increases. Interestingly, the decrease in tariffs strongly influences the number of generating assets installed, unlike with the increase in tariffs. This is true for both summer and winter. The decision to install additional assets is not just influenced by the tariffs but also by the operational cost of grid storage.
In both summer (Figure 16) and winter (Figure 17), the pattern analysis of the scaled grid profits for each tariff level suggests that each of the “Linked” methodologies performs comparably, with very little to differentiate between them in terms of individual grid profits and overall system profits. There is an exception in the case of winter Test Set 1, in which GA Order Linked performed better than its peers. It is noticeable from the pattern of the results that as the tariffs increase, the profits decrease. Therefore, there can be a situation when the tariffs are sufficiently high so as to make the “Linked” methodologies less profitable than the Stand-Alone Sequential. This situation probably comes about when there are sufficiently high tariffs, low installed grid storage and generation capacity, and high generation installation costs.


For both the summer (Figure 16) and winter (Figure 17), the pattern demonstrates that an increase in tariffs does not drastically affect the underutilized energy metric; the metric remains mostly consistent for Test Set 1, 2, and 3. But, in the case in which the tariffs are reduced, it is observed that the underutilized energy metric increases significantly. This is explained by the fact that when tariffs are reduced, more energy is purchased from EA and EB instead of from the battery, and this is reasonable given that the battery SoC is one of the two factors that makes up the underutilized energy metric. It is important to note that again the operational cost of the battery plays an important role in this metric. For both seasons, it is observed that the tariffs influence the GA Order strongly, whereas the tariffs influence the Profit Order differently for summer and winter. In summer, the profit order is largely consistent, whereas in winter, the profit order is less consistent, but not drastically different.
It is observed from the individual grid and overall system analysis that the GA consensus methodology performs less consistently among its peer “Linked” consensus methodologies in individual grid, but performs consistently in overall system with the profit metric in summer. While in winter, GA performed better in one of the five test sets with the profit metrics, in the remaining four test sets, it was almost consistent with its peer “Linked” consensus methodologies. The following figures, that is, Figure 16 and Figure 17, show the scaled grid profit plots and the Grid Data Orders for Stand-Alone Sequential, Linked Sequential, Profit Order Linked and GA Order Linked methodologies for each of the five different tariff level test sets for both the summer (Figure 16) and winter (Figure 17) seasons.
6 CONCLUSION AND FUTURE SCOPE
This article investigates energy-as-a-service business models for smart contract formation. The smart contract facilitates peer-to-peer energy transactions in a VPP through a local energy market. This article also proposes a novel evolutionary computing strategy and a comparison among existing strategies for smart contract formation. In the first layer, a generation and transmission expansion planning model, as presented in Reference 51 is used for the simulation. In the second layer, the proposed strategies are implemented on top of the MILP model. Simulations are conducted for 10 cases with 10 grids in each case for summer and winter seasons.
The analysis of the simulation results illustrates that the proposed evolutionary computing strategy performs better than other strategies in the winter season. Meanwhile, in summer, all strategies perform similarly to one another. Since the peak demand period used in this study is in winter, the winter results are particularly informative. In winter, the dependence on external energy resources is higher due to higher demand, whereas peak demand and generation are spread apart. The proposed evolutionary strategy outperforms other methods in 4 of 10 scenarios to optimally schedule the smart contract formation because the proposed strategy maximizes total profit while minimizing energy losses. There is a pattern where the proposed evolutionary strategy outperforms others. Moreover, the overall analysis demonstrates that energy-as-a-service business models are profitable and provide better utilization of the existing capacity of generation units. The proposed strategy can be used in preparing policies for smart contract formations. The energy landscape is becoming more distributed and decentralized. The proposed model and analysis contribute to energy transactions and EaaS models for modern distributed energy resources. The proposed approach has a high value for real-world industries, as it allows a VPP owner to utilize the proposed model and strategies to determine how to best organize transactions. In addition, a small-scale producer could utilize the model to optimally plan the capacity of assets to maximize the profits.
The current article is focused on the coordination strategies for EaaS. The explanation of the strategies is now extended with more details. An additional figure is also added to better clarify the simulations and results. However, the analysis does not extend to market clearing mechanisms. In a subsequent work, the authors will address the market clearing problem with a proposed evolutionary computing strategy for smart contract formation.
In a future research, demand side flexibility could be investigated among the portfolio of technologies in a VPP. In addition, the transparency of energy flows to verify their origin could also be investigated. Also, the performance metrics may further be refined, including other metrics. Finally, different heuristic techniques can be further explored to investigate how the result changes in comparison with the GA.
ACKNOWLEDGEMENTS
This work is supported by the Estonian Research Council grant PUTJD915, the Ministerio de Economía y Competitividad under contract TIN2017-84553-C2-2-R and the Ministerio de Ciencia e Innovación under contract PID2020-113614RB-C22.
Open Research
DATA AVAILABILITY STATEMENT
Research data are not shared.

