

A hybrid attention mechanism for blind automatic modulation classification
Funding information: the Foundation of the Hebei Key Laboratory of Electromagnetic Spectrum Cognition and Control, The Science Foundation of Ministry of Education(MOE) of China and China Mobile Communications Corporation, Grant/Award Number: MCM20200106
Abstract
Recently, deep leaning has been making great progress in automatic modulation classification, just like its success in computer vision. However, radio signals with harsh impairments (oscillator drift, clock drift, noise) would significantly degrade the performance of the existing classifiers. To overcome the problem and explore the depth reason, a hybrid attention convolution network is proposed to enhance the capability of feature extraction. First, a spatial transformer network module with long short-term memory is introduced to synchronize and normalize radio signals. Second, a channel attention module is constructed to weight and assemble feature maps, exploring global feature representations with more context-relevant information. By combining these two modules, a relatively lightweight classifier with complex convolution layer for final classification is further researched through visualization. Moreover, different structures of attention module are compared and optimized in detail. Experimental result shows that our proposed hybrid model achieves the best performance among all compared models when SNR is upper than  7 dB, and it peaks at 93.448
7 dB, and it peaks at 93.448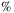 at 0 dB, 2.7% higher than that of CLDNN and 97.560
at 0 dB, 2.7% higher than that of CLDNN and 97.560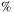 at 20 dB, 8.2% higher than that of ResNet. And our model can be more efficient after a trade-off between accuracy and model size.
at 20 dB, 8.2% higher than that of ResNet. And our model can be more efficient after a trade-off between accuracy and model size.
Open Research
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available from the corresponding author upon reasonable request.

