

Inversion of terrestrial ecosystem model parameter values against eddy covariance measurements by Monte Carlo sampling
Abstract
Effective measures to counter the rising levels of carbon dioxide in the Earth's atmosphere require that we better understand the functioning of the global carbon cycle. Uncertainties about, in particular, the terrestrial carbon cycle's response to climate change remain high. We use a well-known stochastic inversion technique originally developed in nuclear physics, the Metropolis algorithm, to determine the full probability density functions (PDFs) of parameters of a terrestrial ecosystem model. By thus assimilating half-hourly eddy covariance measurements of CO2 and water fluxes, we can substantially reduce the uncertainty of approximately five model parameters, depending on prior uncertainties. Further analysis of the posterior PDF shows that almost all parameters are nearly Gaussian distributed, and reveals some distinct groups of parameters that are constrained together. We show that after assimilating only 7 days of measurements, uncertainties for net carbon uptake over 2 years for the forest site can be substantially reduced, with the median estimate in excellent agreement with measurements.
Introduction
Only about half of the increasing emissions of CO2 from human activities currently remain in the atmosphere (Prentice et al., 2001). The remainder is taken up by both the oceans and the terrestrial biosphere, to roughly equal amounts (Joos et al., 2003). This current carbon sink in the terrestrial biosphere is, by some models at least, predicted to turn into a source (Cox et al., 2000; Cramer et al., 2001; Friedlingstein et al., 2003). Better quantification of the exchange fluxes of CO2 between the terrestrial biosphere and the atmosphere and better understanding of the underlying processes are therefore of foremost importance for the design of efficient climate protection strategies. Terrestrial ecosystem models (TEMs) have been used extensively to study the processes leading to either carbon loss or gain by the land biota (McGuire et al., 2001; Prentice et al., 2001). However, results still vary significantly because of differences between models (Cramer et al., 1999). While only very few studies using TEMs have considered uncertainties in fluxes as a result of parameter uncertainties, Knorr & Heimann (2001a, b) have shown that uncertainties of TEM process parameters lead at least to the same spread of simulated atmosphere–vegetation carbon fluxes as intermodel differences.
More recently, Kaminski et al. (2002) have shown that TEMs can be combined with atmospheric transport inversion techniques. By using an additional process model and a Bayesian approach to parameter inversion, such inversions are both better constrained than transport inversions and allow inferences about the underlying processes. An example of a more complex Carbon Cycle Data Assimilation System (CCDAS) is given by Rayner et al. (2005). CCDAS requires one to specify prior means and error covariance matrices of model parameters, as an approximation of the prior probability density function (PDF) of parameters. To generate and analyze such a PDF is one purpose of the present study.
Few attempts exist at quantifying uncertainty ranges based directly on experimental data (Knorr, 2000; White et al., 2000; Knorr & Heimann, 2001a). It is, therefore, of general interest to utilize the still growing amount of eddy covariance measurements of CO2 and water fluxes (FLUXNET, Global Carbon Project, 2003) for ecosystem model parameter estimation. Wang et al. (2001) used a non-Bayesian parameter optimization and showed that for their model, up to five parameters could be estimated on the basis of eddy covariance measurements of CO2, water, heat and ground heat fluxes. Prior knowledge of parameter values was used to initialize the parameters that were optimized, to set the parameters that remained unaffected by the optimization, and to determine reasonable limits for the space of parameter solutions allowed. The result is a set of model parameters that are either based fully on prior estimates, or fully on the inversion against measurements.
Here, Bayesian methods offer a more consistent approach by combining prior knowledge with the additional information gained from the inversion. This does not only allow the simultaneous determination of all parameters, it also allows considering prior knowledge consistently for all parameters. Weakly constrained parameters are, therefore, given an appropriate uncertainty range instead of being excluded a priori from the optimization. The method can be applied to global scale inversions (Rayner et al., 2005), or to sites using flux measurements as a model constraint.
With this contribution, we will demonstrate a general method for Bayesian parameter estimation of complex, process-based TEM, where parameter uncertainty ranges are derived from systematic sampling of the complete PDF. By comparing prior and posterior uncertainty ranges of parameters, it will be determined which parameters can be constrained by eddy covariance measurements of CO2 and water fluxes for a given set of prior parameter uncertainties and for a given measurement error, using a particular TEM. The analysis of covariances is then used to determine which parameter values cannot be determined independently by the data. Finally, simulations with the constrained model – using both the complete PDF or its first two moments – are carried out for much longer time series than those used during the parameter estimation, to test the validity of the parameterization across time. Here, we also assess whether an approximation to the full PDF as used by CCDAS (means and error covariances) sufficiently represents uncertainties in net CO2 fluxes. The method is thus presented as a prototype for an initial step of CCDAS that allows the exploitation of widely available site-specific flux data through constraining model parameters.
Methods
Monte Carlo inversion
 (1)
(1) (2)
(2) ((3a))
((3a)) ((3b))
((3b)) ((4a))
((4a)) ((4b))
((4b)) (5)
(5) (6)
(6)The complete method of Monte Carlo inversion is described in detail by Mosegaard & Tarantola (1995) and reviewed by Mosegaard & Sambridge (2002). We always perform one iteration starting from the prior set of parameters (i.e. p1=p0). For some cases (see Results), we add an ensemble of Monte Carlo integrations with varying starting points in the way suggested by Gelman et al. (1995). To generate subsequent values p2, p3, … in each series, a new point is tried by varying all vector elements by some step, Δp, chosen with a Gaussian distributed random number generator with mean zero and standard deviation set for each parameter separately to the prior uncertainty times an appropriately chosen step-length factor. The new point, pi+Δp at step i of the iteration, is accepted or rejected according to a two-step version of the Metropolis algorithm: The first step is always accepted, if ρ(pi+Δp)/ρ(p)≥1, and it is accepted with a probability of ρ(pi+Δp)/ρ(p) if ρ(pi+Δp)/ρ(p)<1. Acceptance with a probability of <1 – the latter case – is carried out by generating a uniformly distributed random number between 0 and 1. Only if this number is less than the chosen probability, the first step is accepted. The second step is assessed in the same way as the first, except that the prior probability ρ(p) is replaced by the likelihood function L(p). Only if both steps are accepted, the next point in the series is pi+1=pi+Δp, else pi+1=pi (i.e. the previous point is chosen again). We adjust the step length for each parameter to values which lead to an average acceptance rate of the new points around 0.3 (Gelman et al., 1995). Only the second step requires model execution.
Simulations
As a demonstration of the Monte Carlo method, we chose two different photosynthesis models and two setups with a reduced and a more extensive part of the Biosphere Energy-Transfer Hydrology (BETHY) model. The reduced version of BETHY is used together with the C4 photosynthesis model and excludes the heterotrophic respiration part. Compared with the C3 version with heterotrophic respiration, this reduces the number of free parameters from 23 to 14. The C4 version uses eddy covariance measurements, by Kim & Verma (1991), from the first ISLSCP field experiment (FIFE) grassland experimental site in Kansas, and the C3 version data from the Loobos pine forest site in the Netherlands (Dolman et al., 2002).
Input and flux data
The FIFE site in north-eastern Kansas, USA (39°03′N, 96°32′W) was dominated by the C4 tallgrass species Andropogon gerardii, Sorghastrum nutans and Panicum virgatum. The implementation of BETHY for this site is also described by Knorr (1997). In this case, we assimilated daytime data of net canopy assimilation (gross primary productivity (GPP) minus total-canopy leaf respiration) derived from eddy covariance measurements of net ecosystem exchange (NEE) by subtracting soil and plant, excluding leaf, respiration rates derived from night-time CO2 fluxes, for 4 days representative of the 1987 growing season: June 5, July 2, July 30, and August 20. July 30 was the only date with severe drought. We also assimilated daytime canopy conductance values for the same dates and times that were obtained through inversion of the Penman–Monteith equation against daytime latent energy flux measurements. Photosynthetically active radiation (PAR), air temperature, vapor pressure deficit (VPD) and relative plant available soil moisture (w/wm, Eqns (A12) and (A17)) were used as input data. All data were taken from Kim & Verma (1991). Global radiation was computed from Julian day, longitude and latitude, while wind speed and free-air CO2 concentration were left constant at 3 m s−1 and 355 ppm, respectively. We used a relative uncertainty of 20% for both net canopy assimilation and canopy conductance, with a threshold of 3.0 μmol m−2 s−1 and 1.5 mm s−1, respectively.
The vegetation at the Loobos site (the Netherlands, 52°10′N, 5°74′E) was dominated by Pinus sylvestris with an understory of the grass Deschampsia flexuosa (Dolman et al., 2002). Global radiation, PAR, air temperature, ambient CO2 concentration, wind speed, VPD and total soil water content, wtot, were used as input data. Soil water content at wilting point (2.5% vol.) and at field capacity (12.4% vol.) were estimated from soil texture information. We assimilated half hourly values of NEE and latent energy flux (LE) from 7 days, 5 in 1997 (January 14, March 3, July 9, September 24, October 25), and 2 in 1998 (May 15, August 9). Those days were chosen to represent typical conditions of the various seasons, have as complete data coverage as possible, and at least some cloud-free conditions during daytime. We also required that there was no rainfall during the day and the day before so that soil and canopy evaporation could be neglected. The uncertainty of NEE was taken to be 20% of NEE during day and 50% of NEE during night, accounting for low wind speed and little turbulence during night-times. The minimum uncertainty threshold was set to 3.0 μmol m−2 s−1. Uncertainties of LE were considered to be 20% of LE, with a threshold of 22.0 W m−2. Uncertainties of input data were not considered for either site.
Prior model parameter values and uncertainties
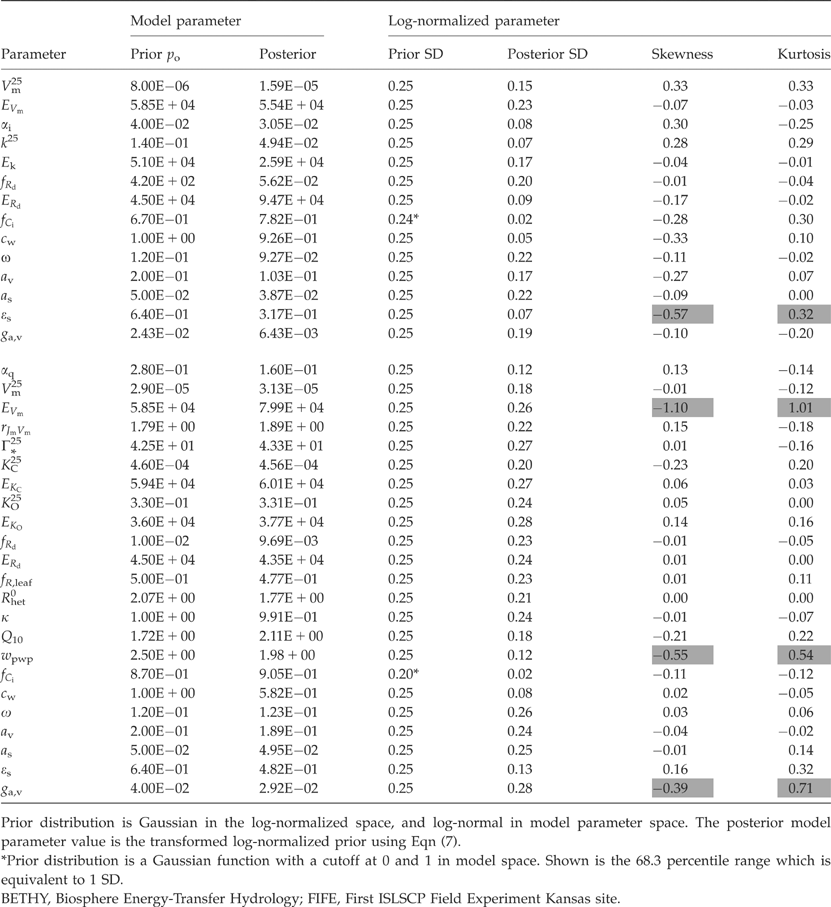
All model parameters and their prior values are listed in Table 1. Their choice is based on the model description of BETHY (Knorr, 2000), with a few exceptions: the value for rJmVm was derived from data by Wullschleger (1993), Medlyn et al. (2002) and Leuning (2002); k25 and Ek follow Knorr (1997); ERd was set to the value cited by Kim & Verma (1991); fR,leaf was modified for one plant respiration rate instead of separate maintenance and growth respiration; Rhet0 was set to a value for which the heterotrophic respiration model (at a priori parameter values) driven with data from the Loobos site reproduces the range of measured soil respiration rates given in Raich et al. (2002) and Reichstein et al. (2003); Q10 follows Raich et al. (2002); wpwp was derived from soil texture information and soil water potential relations from Schachtschabel et al. (1992); and av was set to the upper bound of values given by Knorr (2000).
| Symbol | Description | Value | Unit | Eqn | C3 | C4 |
|---|---|---|---|---|---|---|
| Photosynthesis | ||||||
| αq | Quantum efficiency of photon capture (C3) | 0.28 | mol(e−) mol−1 | A1c | X | |
| Vm25 | Maximum carboxylation rate at 25°C (C3) | 29 | μmol m−2 s−1 | A2 | X | |
| Vm25 | Maximum carboxylation rate at 25°C (C4) | 8 | μmol m−2 s−1 | A2 | X | |
| EVm | Activation energy of Vm | 58 520 | J mol−1 | A2 | X | X |
| rJmVm | Ratio of Jm to Vm at 25°C | 1.79 | – | A3 | X | |
| Γ*25 | CO2 compensation point without dark respiration at 25°C | 42.5 | μmol mol−1 | A4 | X | |
| KC25 | Michaelis–Menten constant for carboxylation at 25°C | 460 | μmol mol−1 | A5 | X | |
| EKC | Activation energy of KC | 59 356 | J mol−1 | A5 | X | |
| KO25 | Michaelis–Menten constant for carboxylation at 25°C | 0.33 | mol mol−1 | A6 | X | |
| EKO | Activation energy of KO | 35 948 | J mol−1 | A6 | X | |
| αi | Quantum efficiency of photon capture (C4) | 0.04 | mol(CO2) mol−1 | A7 | X | |
| k25 | CO2 specificity at 25°C | 0.14 | mol m−2 s−1 | A8 | X | |
| Ek | Activation energy of k | 50 967 | J mol−1 | A8 | X | |
| Carbon balance | ||||||
| fRd | Ratio of leaf dark respiration at 25°C and Vm25 (C3) | 0.011 | – | A10 | X | |
| fRd | Ratio of leaf dark respiration at 25°C and Vm25 (C4) | 0.042 | – | A10 | X | |
| ERd | Activation energy of leaf dark respiration | 45 000 | J mol−1 | A10 | X | X |
| fR,leaf | Ratio of canopy to total plant respiration | 0.5 | – | A11 | X | |
| R het 0 | Heterotrophic respiration at 0°C and field capacity | 2.07 | μmol m−2 s−1 | A12 | X | |
| κ | Soil moisture factor of heterotrophic respiration | 1 | – | A12 | X | |
| Q10 | Temperature dependency of heterotrophic respiration | 1.72 | – | A12 | X | |
| Stomatal control | ||||||
| wpwp | Soil water content at permanent wilting point | 2.5 | vol% | – | X | |
| fCi | Non water limited ratio of Ci,0 and Ca (C) | 0.87 | – | A14 | X | |
| fCi | Non water limited ratio of Ci,0 and Ca (C4) | 0.67 | – | A14 | X | |
| cw | Maximum water supply rate of root system | 1 | mm h−1 | A17 | X | X |
| Energy and radiation balance | ||||||
| ω | Single scattering albedo of leaves | 0.12 | – | – | X | X |
| av | Albedo of close vegetation surface cover | 0.2 | – | A18 | X | X |
| as | Fraction of solar radiation absorbed by soil under close canopy | 0.05 | – | A18 | X | X |
| ɛs | Sky emissivity factor | 0.64 | – | A19 | X | X |
| ga,v | Vegetation factor of atmospheric conductance | 0.04 | – | A20 | X | |
- BETHY, Biosphere Energy-Transfer Hydrology.
 (7)
(7)  |
An exceptional model parameter is fCi, for which we require 0≤fC≤1. Instead of a log-normal distribution in model parameter space, we choose a probability distribution that is defined by a normal distribution but is cut off at 0 and 1. fCi,0 is the prior estimate of fCi, and fCi=pkfCi,0 replaces Eqn (7), where k is the parameter index for fCi.


Results
We will, first, show results to demonstrate convergence of the algorithm. Next, optimized parameter values will be described by their means, standard errors, and covariances, all in the space of log-normalized parameters (cf. Eqn (7)). Comparison with prior means and errors indicates about how many parameters we have learned something through the assimilation of the eddy covariance data. We also assess for which parameters the posterior PDF differs from the Gaussian distribution assumed for the prior PDF. For the Loobos site, we eventually compute the cumulative NEE with and without optimized parameters over a period of 2 years to test the validity of parameterizations across time and to assess to what degree the inversion has lead to a constraint on the modeled longer-term ecosystem carbon balance.
Convergence of the algorithm
To insure convergence, we performed rather long integrations with 500 000 iterations (and more in one case). For the two cases with 0.25 prior uncertainty, we produced a series of six independent simulations starting from different points in parameter space: the prior parameter vector, p0={1, …, 1} in the space of log-normalized parameters, and points shifted away from the estimated posterior optimum, p′, by one to several times the posterior standard deviations, σ′={σ′1, …, σ′n} estimated from preliminary simulations. For FIFE, the starting points were p0, p′+σ′, p′+2σ′, p′+3σ′, p′−σ′, p′−2σ′, for Loobos p0, p′+2σ′, p′−2σ′, p′+4σ′, p′+4{+σ′1, −σ′2, +σ′3, …} and p′−4{+σ′1, −σ′2, +σ′3, …}. Sampling was done at every 10th iteration to avoid correlations between subsequent samplings (i.e. 500 000 iterations yielded 50 000 samplings of parameters of interest sampled according to Eqn (5)). To determine at which iteration the sequences have converged to a common maximum, as opposed to sampling around local maxima, we applied Gelman's criterion of convergence (Gelman et al., 1995) for all parameters. This test of convergence, designed for practical purposes, yields a reduction factor defined as the square root of the ratio of the mean variances of the various sequences divided by the variance of the means yielded by each sequence. This reduction factor is sampled from exactly the second half of the series up to the iteration indicated (see below the discussion of ‘burn-in time’, and Fig. 1e, f). If all sequences sample the same area of the parameter space, the reduction factor will approach a value of one, values much greater than one indicate sampling of different regions around local minima by the different sequences.

Convergence of the Monte Carlo inversion for 0.25 prior uncertainty of the log-normalized parameters, for the FIFE (left: a, c, e), and the Loobos site (right: b, d, f). (a, b) Estimated mean of selected parameters depending on number of iterations; (c, d) phase diagram of the two contributions to the total cost function, measuring deviation from prior parameters and between measured and modeled diagnostics (=fluxes), for sequences with varying starting points; (e, f) Gelman's reduction factor for the same parameters as above, and for two parameter products. The selected parameters are: the slowest converging, one fast converging, and the one most highly correlated with the first.
The parameters that took longest to reach a common maximum, according to Gelman's criterion, were αi for FIFE and fCi for Loobos. The evolution of the estimated mean values is shown in Fig. 1a and b, respectively, again for every 10th iteration. Also shown are one fast converging parameter, and the parameter that was most highly correlated to the first. Note that in Fig. 1b, EVm appears to be converging more slowly than fCi. The explanation is that EVm remains highly uncertain and, as we will see later, assumes an extremely non-Gaussian distribution within the posterior PDF. In general, parameters for the FIFE site seem to converge faster than for Loobos, which would be expected for an inversion with 14 instead of 23 parameters.
A more convenient way to visualize convergence of the sampling sequences is a phase diagram using the costs of the prior probability (Eqn (4b), costs of parameters) and the misfit in the Likelihood function (Eqn (3b), costs of diagnostics) as the two axes (Gelman et al., 1995). As Fig. 1c and d shows for both sites and 0.25 prior uncertainty, all sequences appear to converge against a common global cost function minimum (maximum of the PDF), despite widely varying starting points. The convergence, however, is less straight for FIFE, where a local minimum with a cost of diagnostics of around 500 is initially reached by some of the simulations. Analysis of the other simulations (not shown) reveals that the sequence with 0.125 prior uncertainties remains even longer in a similar local minimum until it reaches a region with costs of diagnostics and parameters both around 200. The simulation with 0.5 prior uncertainty does not seem to find a local minimum and converges more rapidly, with costs of diagnostics around 100, and costs of parameters around 35.
The ratio of the costs of diagnostics over parameters in the region of the global minimum gives an indication of how strongly the inversions are constrained by observations. For the FIFE site, this ratio varies between around 1, 2, and 3 for 0.125, 0.25, and 0.5 prior uncertainties. For Loobos, the costs of diagnostics decrease only about 10% from 0.125 to 0.5 prior uncertainties, and the costs of parameters all lie around 40, giving an almost constant ratio of around 10. Apparently, the more reduced model version with 14 parameters needs rather weak constraints on parameters to converge efficiently, and is still less constrained by observations than the more direct inversion against NEE and LE. Note, however, that the FIFE inversion used only 4 days and only data from daytime fluxes.
To determine a practical initial cut-off for iterations before convergence to the global PDF maximum, the so-called ‘burn-in time’ with length n iterations, we used again Gelman's test (Gelman & Rubin, 1992; Cowles & Carlin, 1996). It requires that the reduction factor computed for the ensuing n iterations (i.e. iterations n+1 to 2n) reaches a value of around 1.2–1.4 for all sampled quantities of interest. Figure 1e and f show this reduction factor for the same parameters as Fig. 1a and b, together with the values of the product of the slowest converging parameter with the two others, as a function of the total number of simulations, variable burn-in time plus ensuing iterations of the same length. Products are required to compute parameter covariances and appear to converge at least as rapidly as the slowest parameter. (The reduction factor is always applied to the second half of the iterations up to the number indicated. A burn-in time of n=50 000 thus corresponds to 100 000 iterations.) To be on the safe side, we chose a burn-in time of length n=50 000 iterations.
Convergence of parameters for the cases with 0.125 and 0.5 prior uncertainties was evaluated by plotting expected values of all parameters against the length of the burn-in time. The same burn-in time of 50 000 iterations was found to be sufficient for all cases except for FIFE with 0.125 prior uncertainty, where 1 000 000 iterations were chosen instead. For the case of 0.25 prior uncertainty, we carried out six sequences, for the other only one. For each sequence, we continued with another 450 000 iterations after burn-in (including the FIFE 0.125 case). Because only every 10th iteration was sampled, this yielded 45 000 parameter samplings for 0.125 and 0.5 prior uncertainties, and 270 000 samplings from six sequences for 0.25 prior uncertainties. Each sequence of 500 000 iterations took ca. 5 h central processing unit time on a Linux PC workstation with 1.9 GHz clock speed.
Parameter change and uncertainty reduction from constraining with eddy covariance data
Means and standard deviations can be estimated directly from the samplings of the posterior PDF in the space of the log-normalized parameters. As the parameters represent different processes, comparison with prior means and uncertainties provides valuable information on those processes about which we can learn most through the use of eddy covariance data. The means and ranges corresponding to one standard error are shown in Fig. 2 for all prior and posterior parameter values. For the non-Gaussian prior distribution of fCi, we show the corresponding percentiles.

Prior and posterior parameter values and uncertainties for the log-normalized parameters (transformation to model parameters see Eqn (7)). The boxes show means and one standard deviation of assumed prior parameters (SD=0.125, 0.25, 0.5). Crosses show the posterior means, and error bars 1 SD of the posterior parameters. Left: Biosphere Energy-Transfer Hydrology (BETHY) model C4 version constrained with data from FIFE site; right: BETHY C3 version constrained with data from Loobos site. The axis on the right hand side shows the model parameter values divided by their respective priors for comparison (does not apply to parameter fCi).
For the C4 FIFE site, patterns of parameter change are consistent between versions 0.25 and 0.5, with version 0.125 being similar for most parameters, except for those two of the CO2 specificity, k. The standard rate, k25, and its activation energy, Ek, are decreased by a large amount when prior uncertainties are large, while they are not affected by the inversion when prior uncertainties are small. We interpret this result in the following way: both parameters describe one of three co-limiting rates that determine C4 photosynthesis (Eqn (A7)). In one case, the priors are set in such a way that the rate Jc, is never limiting the actual rate A. Once prior uncertainties are increased, the inversion gains more freedom and finds a solution where all three rates, Je, Jc, and Ji, are limiting and agreement with observations is significantly improved (see lower cost of diagnostics between the local and the global minimum in Fig. 1c).
For the Loobos C3 site, patterns of parameter changes are similar for versions 0.125 and 0.25. The pattern of version 0.5 differs from these for at least five parameters: Γ*25, KC25, ERd, k and av. For the photosynthesis parameters, there is a consistent pattern of lower quantum efficiency, αq, with little change in maximum carboxylation rate, Vm25, and an increase in the carboxylation rate's activation energy, EVm. For others, there is no consistency: the direction of change depends on the prior uncertainty (for rjmVm, Γ*25, KC25), or changes are small overall. For the respiration parameters, there is a consistent increase in Q10, and a decrease in the overall heterotrophic respiration expressed through Rhet0 (except for 0.125 prior uncertainty). As for FIFE, the posterior values of the stomatal parameters cw and fCi are almost independent of the prior uncertainty ranges, and there is a universal downward adjustment of the third, wpwp.
Another quantity that measures the gain in information after inversion against the eddy covariance data is the relative reduction in uncertainty, defined as 1−σposterior/σprior, where σ is the parameter's standard deviation. For fCi, with its non-Gaussian prior distribution, we again use the equivalent percentile range for σprior. If this value comes close to one, we have gained almost complete knowledge of the particular parameter concerned. Because σ is derived from the complete PDF, cases where this value is less than 0 are also possible. The relative reduction in uncertainty is shown in Fig. 3.

Relative reduction of uncertainty of parameter values. Zero or negative relative error reduction indicates that no information about a particular parameter could be gained, one would mean perfect knowledge of the inversion. Left: Biosphere Energy-Transfer Hydrology (BETHY) model C4, FIFE site; Right: BETHY C3, Loobos site. Gray shadings denote (from left to right): photosynthesis, carbon balance, stomatal control, and energy/water balance.
For both sites, most information is gained for the stomatal parameters, in particular fCi. This is not a great surprise, as stomata regulate water-use efficiency, (i.e. the ratio of lost water to gained carbon dioxide molecules), and the fluxes of both (or derived quantities) are just the information that is assimilated. The next best-constrained process is photosynthesis, with most information gained for quantum efficiency (αi or αq for C3 or C4), maximum carboxylation rate, Vm25, and for C4 the functionally similar CO2 specificity, k25 (except, again, for FIFE 0.125). Within the energy and radiation balance, most information is consistently gained for the sky emissivity parameter, ɛs. Only in some cases, information is gained about albedo (av) and aerodynamic conductance (ga,v). For FIFE, the two respiration parameters are consistently constrained, while for Loobos, only very little can be learned about either autotrophic or heterotrophic respiration. There seems to exist a principle difficulty to distinguish between autotrophic and heterotrophic respiration on the basis of net CO2 flux measurements. This result should caution us against the use of night-time CO2 flux data to derive GPP from NEE, here implicit in the data from the FIFE site.
Covariances between parameters
Covariances between parameters, given in their log-normalized form in Table 2 for 0.25 prior uncertainties and both sites, can be used to find groups of parameters that tend to be constrained together. For FIFE, we rather do not find such distinct groupings of parameters. Instead, we find that 11 of the 14 parameters from different parts of the model are strongly correlated with other parameters, with a log-normalized covariance (=correlation coefficient) of up to 0.91 for the pair cw and ɛs. Two parameters, fRd and ɛs, have a correlation of over 0.30 to four other parameters. For Loobos, however, we can identify some distinct groups of parameters for which errors are correlated. The first such emerging group consists of the six first photosynthesis parameters (αq, Vm, EVm, rjm, Γ*25, KC25) plus the stomatal parameter, fCi. These are linked to a second energy balance group consisting of ɛs and ga,v via fCi, EVm and αq. fCi is only weakly correlated to the other, soil moisture-related stomatal parameter, cw. This latter parameter cannot be separated from the wilting point parameter, wpwp: the covariance in log-normalized space reaches 0.75, which indicates that the effect on NEE and LE of changes in one parameter is compensated by changing the other parameter in the same direction. A third group is formed by the three heterotrophic respiration parameters, Rhet0, κ, and Q10: these are linked to the first group by a high log-normalized covariance between Q10 and EVm.
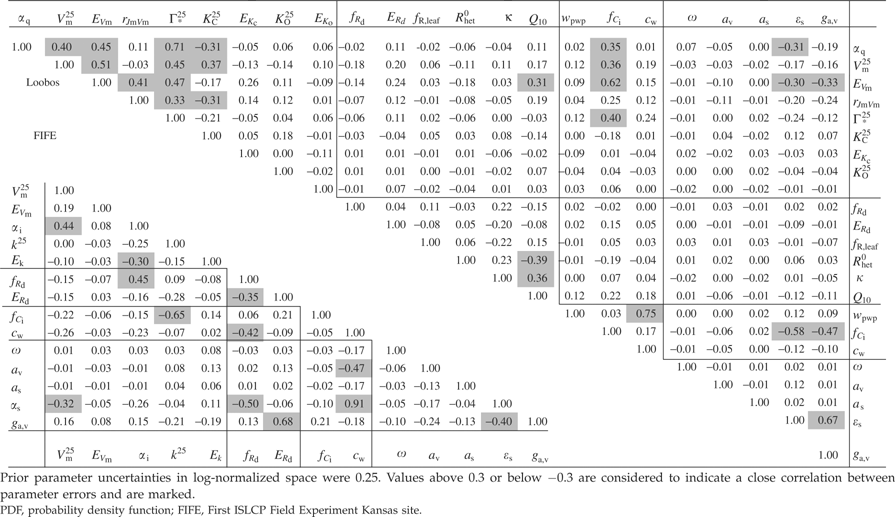 |
There is one important difference between the two sites that affects parameter correlations: for FIFE, canopy conductance is assimilated, whereas for Loobos it is (through latent heat flux) the measured transpiration rate. For example, the correlation between cw and ɛs is 0.91 for FIFE, but –0.12 for Loobos. Also, cw at Loobos is highly correlated with wpwp, a parameter that is absent at FIFE. For both sites, increasing cw leads to a higher root supply rate and an increase in the canopy conductance and transpiration rate, all other parameters being equal. Increasing ɛs, through increasing net radiation, increases atmospheric demand (D in the model description, see Appendix), and through this the transpiration rate. As stomata respond to atmospheric demand by closing (Eqn (A17)), increasing ɛs, leads to a decrease in canopy conductance. To match the quantity that is assimilated, both cw (or wpwp) and ɛs have either opposing effects (FIFE: on canopy conductance) and are correlated, or have an effect that goes in the same direction (Loobos: on transpiration) and must therefore be anticorrelated to compensate each other.
Analysis of the posterior PDF
So far, we have only analyzed means and covariances derived from the PDF of the posterior parameters. Table 3 lists the prior and posterior means of both the model and the log-normalized parameters. We will now assess whether the assumption of Gaussian posterior distributions is adequate – the advantage would be easy use of the PDF in a global CCDAS (see Introduction). The analysis is based on the medium case of 0.25 prior uncertainty of log-normalized parameters. The skewness and kurtosis of the PDF projected onto each log-normalized parameter is also listed in Table 3. Skewness measures whether a distribution is ‘leaning,’ or skewed, towards either the left (i.e. values smaller than the mean, negative skewness), or the right (positive skewness). Kurtosis indicates ‘peakedness’ relative to a Gaussian distribution, where distributions flatter than Gaussian have negative values (Storch & Zwiers, 1999). Most parameters show only small deviations from a Gaussian distribution, with skewness often slightly negative.
A few parameters, however, are more negatively skewed and some have a markedly ‘pointed’ distribution (high positive kurtosis): ɛ for FIFE, and EVm, ga,v and wpwp for Loobos (see Fig. 4). EVm, ga,v also show an increase in the standard deviation from prior to posterior. If the distribution of a parameter is much different from Gaussian, then estimation techniques that use the gradient in parameter space to find the cost function minimum, and second derivatives of the cost function to derive parameter uncertainties, will give erroneous results. For fCi (FIFE), this would lead to a mean of 1.11 instead of 1.09, and a slight underestimate of the uncertainty. The effect would not be large for wpwp (Loobos), either, and still quite acceptable for ga,v, given the generally large uncertainties.

Probability distributions of selected parameters from FIFE (a) and Loobos (b–d) for a prior uncertainty of 0.25 in parameter space. Comparison of importance sampling, approximating the true distribution, with the prior probability density function (PDF) and to posterior Gaussian PDF computed from mean and standard deviation. Additionally, the mean, standard deviation, skewness and kurtosis are given for the posterior distribution.
Extrapolation of results in time
We have obtained a constrained parameter PDF for the BETHY C4 and C3 models from 4 or 7 selected days of eddy covariance data, respectively. The question to ask now is how the gained process knowledge, expressed through reduced parameter uncertainty, translates into reduced uncertainty about the quantity of highest interest: the net sink at the site over a longer time period. For that purpose, we have computed the cumulative NEE over a period of 2 years at the Loobos site, complete with 95% confidence ranges, from the prior, the posterior Gaussian, and the full-posterior PDF. The posterior Gaussian PDF approximates the full PDF by using only the means and the error covariance matrix. As Fig. 5 shows by the green area, prior uncertainties about parameter values of BETHY were consistent with the Loobos site being both a strong sink (positive NEE), or a moderate source of carbon (negative NEE) over the 2 years. After constraining the model, the 95% confidence range lies outside of the median prior estimate and Loobos is now very definitely identified as a CO2 sink. This means that extrapolating 7 days of NEE and LE data through the assimilation procedure resulted in a sink estimate that was both significantly different from the best prior estimate and significantly different from zero. Further, we find that using the full PDF in parameter space results in only about half of the uncertainty in NEE over the 2 years compared with using a PDF derived from parameter means and covariances. Skewness and kurtosis of the full PDF of the cumulative NEE can also be relatively large.

Cumulative net ecosystem exchange (NEE) for 2 years, using the results from the inversion against 7 days of NEE and latent energy flux, for the Loobos site. Green: prior uncertainty range, yellow: posterior uncertainty range using posterior mean and error covariance (Gaussian posterior PDF); red: posterior uncertainty range with full PDF; blue: measurements, dashed: missing data (NEE=0 assumed). Positive values of NEE indicate a terrestrial carbon sink.
Note that this result still depends on the prior uncertainty, which was only estimated in a simple and preliminary way for this study. Also, assimilating more days of flux measurements would lead to stronger constraints of model parameters and fluxes, which would lead to even smaller uncertainties of the cumulative NEE. Here, we can instead use the measured NEE of the 2 years, with a few gaps (for which we assumed NEE=0), to validate our time extrapolation (Fig. 5, blue line). With this additional assumption as a point of caution, we arrive at around 25 mol(CO2) m−2 yr−1 or 300 g C m−2 yr−1 net uptake from both the observations and the model simulations. The generally good agreement between modeled (after assimilation) and measured NEE across the 2 years shows that the model is able to capture the main processes that influence this quantity. We therefore suggest, that the method shown here with all available measurements assimilated, could be a superior gap filling method compared with the ones usually employed by the eddy covariance community.
Discussion
We have performed several Bayesian inversions of an ecosystem model, BETHY, constrained by eddy covariance data of carbon and water fluxes. There were two sites, one C3 and one C4, and three sets of assumptions about prior parameter uncertainties. We find that the method works very well, although some care has to be taken to insure algorithm convergence. Compared with non-Bayesian, standard optimization techniques (e.g. Wang et al., 2001), the method treats all parameters equally and simultaneously, and is still able to distinguish between those parameters that can be constrained by the eddy covariance data, and those that cannot. With 4 or 7 days of diurnal data assimilated, the Bayesian part of the cost function in the region of the minimum was between two and 10 times the cost of the measurements, so that the inversion was found to be constrained predominantly by the flux data. Similar to Wang et al. (2001), who used non-Bayesian inversions, we find that typically five parameters can be effectively constrained by the method. Perhaps not surprisingly, two to three of them are stomatal parameters: stomata control the balance between carbon uptake and transpiration at the leaf level, both were assimilated, albeit at the stand level. This shows that leaf-level functional representations can be effectively constrained. One of the parameters, ɛs, strictly speaking, belongs to the external driver of BETHY used in the computation of incoming thermal radiation. This particular result indicates that assimilating accurate radiation data (obliterating the need for ɛs) will likely improve parameter estimation further. We could also constrain parameters describing the light response (αi, αq), and sometimes the temperature response of photosynthesis (k25). It is evident that a sufficient range of environmental conditions must be present during the period for which the data were assimilated to gain information about the dependencies on those conditions. The use of a diurnal cycle and of different dates across the seasons must have helped here, and may explain how well the eddy-flux constrained model performed against the 2-year measurements.
The method also delivers information on the error covariances of parameters. This information can be used to find out which processes can be constrained individually by the assimilation of the eddy flux data. Analysis of the full PDF, only possible by Monte Carlo methods, shows that most parameters tend to have distributions close enough to a Gaussian one for gradient and second-derivative methods to work effectively. These usually require a few orders of magnitude fewer iterations. Only one parameter was identified with a distribution so far away from a normal one that such methods would have underestimated the posterior mean and uncertainty to a large degree.
One straightforward and easy application of the method presented here would be to use the posterior means and covariances of the parameter PDF as priors in a global-scale data assimilation system (cf. Rayner et al., 2005). We expect that using the Gaussian part of the complete PDF will tend to overestimate the uncertainty of the model diagnostics.
We have found that the results of our study depended on the prior uncertainty of the parameter values. This uncertainty itself will depend on the parameter in question, the scale at which the model is applied, and the amount of available information at that scale. Our preliminary results (unpublished) indicate that for Vm25, 0.5 prior uncertainty at the site scale would be a realistic assumption in the log-normalized space if only the functional type of vegetation is known.
We have so far restricted our study to cases that are rather rare when considering the entire FLUXNET archive: we relied on the availability of soil moisture measurements. Applying the method for more sites, however, will be crucial for identifying representative model parameterizations by plant functional type, or some other generalization on which global models necessarily rely. Therefore, we expect to conduct further studies using the complete BETHY model with the full water balance. If no complete data on LAI are available, a phenology scheme may also be included. LAI and soil moisture data could then also be assimilated instead of being used as input. We also suggest using more days and longer periods for assimilation, although we find that only a few days of data already deliver a strong model constraint.
Conclusions
The parameterization of global TEMs for carbon cycle studies poses great challenges. We are confronted with model errors, errors from the finite accuracy of parameter estimation, and representation errors that result from the fact that models need to work with a finite set of idealized vegetation types. This study demonstrates that inversion against eddy covariance data can be a powerful tool for using local measurements to constrain the possible range of ecosystem model parameters. Such information about parameter uncertainties is crucial for understanding to what degree of confidence we can use models to compute the global terrestrial carbon balance.
The advantage of the Monte Carlo inversion technique is that it works even for highly nonlinear models, and that it allows sampling the complete posterior PDF. This can be used to estimate how well methods will work that derive uncertainties from the curvature of the cost function at its global minimum. Because they require far fewer iterations, such methods are better suited for global applications, especially when parameters need to be inverted simultaneously.
Further use of this method will require a careful analysis of the prior uncertainties of model parameters. For the envisaged global applications, it will also be important to repeat the analysis with a sufficient number of sites per major vegetation type in order to gain an understanding of the representation error. We suggest that using such studies to determine prior parameter uncertainties for global carbon cycle data assimilation could be one of the principle applications of data from the growing network of eddy covariance measurement sites. We believe that such a method of extrapolating measurements from local sites to the global scale through the determination and spatial extrapolation of parameters would be the most promising and most adequate route to better global TEMs. These will be crucial for any application aimed at predicting the future response of the carbon cycle to climate change, including atmosphere – vegetation feedbacks.
Acknowledgments
The original eddy flux data used in this study were collected, maintained and generously provided by Eddy Moors, Jan Elbers, Wilma Jans, Han Dolman and colleagues affiliated with the Loobos Research Site in The Netherlands, run by ALTERRA, Green World Research. The authors wish to thank Bart Kruijt and Isabel van den Wyngaert for help with estimating uncertainties of eddy covariance measurements and Thomas Kaminski for useful advice and comments. This work has been financed and supported by the EU project CAMELS, contract number EVK2-CT-2002-00151, within the EU's 5th framework program for Research and Development, and the Max-Planck-Gesellschaft zur Förderung der Wissenschaften, e.V.
Appendix
Appendix: The BETHY model
Overview
We use a process-based model of the coupled photosynthesis and energy balance system, the BETHY scheme, to simulate the exchange of CO2, water and energy between the plant canopy and the atmosphere. BETHY computes absorption of PAR in three layers, while the canopy air space is treated as a single, well mixed air mass with a single temperature. Evapotranspiration and sensible heat fluxes are calculated from the Penman–Monteith equation (Monteith, 1965). Carbon uptake is computed with the model by Farquhar et al. (1980) for C3, and the one by Collatz et al., (1992) for C4 plants. The stomata and canopy model of Knorr (2000) simulates canopy conductance in response to PAR; in the absence of water stress in such a way as to satisfy the demand for CO2. In water-stressed situations, stomata are further closed until transpiration reaches a specific root supply rate that depends on soil moisture. The carbon balance is computed as plant and soil respiration subtracted from the photosynthesis rate to yield net CO2 fluxes. The full version of BETHY, described in Knorr (2000) and Knorr and Heimann (2001a), also contains submodels for soil water balance, snow, canopy and soil evaporation, and phenology, which are not used here. Instead, LAI and soil moisture are treated as external forcing data (elements of s in Eqn (1)). The version of BETHY for C3 vegetation used here has 23 free parameters, while the C4 version has 14. Following is a description of all free model parameters and their meaning in the context of the model. Parameters have been marked as underlined mathematical symbols and are listed in Table 1, complete with their prior values. (Those that do not appear in one of the equations appear underlined in the text.)
Photosynthesis
 ((A1a))
((A1a)) ((A1b))
((A1b)) ((A1c))
((A1c)) ((A2))
((A2)) ((A3))
((A3)) ((A4))
((A4)) ((A5))
((A5)) ((A6))
((A6)) ((A7a))
((A7a)) ((A7b))
((A7b)) ((A7c))
((A7c)) ((A7d))
((A7d)) ((A8))
((A8))Carbon balance
 ((A9))
((A9)) ((A10))
((A10)) ((A11))
((A11)) ((A12))
((A12)) ((A13))
((A13))Stomatal control
 ((A14))
((A14)) ((A15))
((A15)) ((A16))
((A16)) ((A17))
((A17))Energy and radiation balance
PAR absorption is calculated according to the two-flux scheme by Sellers (1985) with three vertical layers of equal LAI. The diffuse fraction of PAR is calculated according to a procedure by Weiss and Norman (1985). Leaf-angle distribution is assumed to be uniform, and the only free parameters for this scheme is ω, the leaf single-scattering albedo.
 ((A18))
((A18)) ((A19))
((A19)) ((A20))
((A20)) ((A21))
((A21))
